Elegir la infraestructura adecuada y las herramientas de monitoreo sintético ya no se trata solo de marcar una casilla de tiempo de actividad; se trata de cerrar la brecha de visibilidad entre la salud de tu backend y la experiencia real del usuario final. En un entorno moderno de DevOps, una falla en tu enrutamiento DNS o una API de terceros latente puede ser tan catastrófica como un fallo del servidor, sin embargo, estos problemas “externos” a menudo pasan desapercibidos por los monitores internos tradicionales.
Esta guía evalúa las 12 mejores herramientas de infraestructura y monitoreo sintético, específicamente curadas para equipos técnicos que necesitan reducir el MTTR (Tiempo Medio de Resolución) y eliminar los “puntos ciegos” en su pila de producción.
Monitoreo Sintético vs. Monitoreo de Infraestructura
Mientras que el monitoreo sintético valida flujos de trabajo funcionales desde ubicaciones globales, el monitoreo de infraestructura proporciona la telemetría granular necesaria para diagnosticar las fallas de hardware y red que causan que esos flujos de trabajo fallen.
| Tipo de Monitoreo | Qué Hace | Casos de Uso Clave & Ventajas |
| Monitoreo Sintético | Imita acciones de usuario, flujos de trabajo guionados y llamadas API programadas | Detecta flujos rotos & desaceleraciones. Comparación entre ubicaciones. Salud de tiempo de actividad/transacciones |
| Monitoreo de Infraestructura | Rastrea: servidores, dispositivos de red, servicios (DNS, TCP/UDP, ping, etc.), & métricas de recursos | Detecta: fallas a nivel de backend & protocolo, interrupciones de servicio y saturación de recursos |
Comparando las 12 Mejores Herramientas de Monitoreo de Infraestructura y Sintético
| Herramienta | Sintético | Infraestructura | Aspectos Destacados | Compensaciones |
| Dynatrace | ✅ | ✅ | Observabilidad impulsada por IA, vinculando flujos de usuario y métricas de backend | Complejo. El costo puede escalar rápidamente |
| Dotcom-Monitor | ✅ | ✅ | Monitoreo sintético y de servicio en una sola plataforma | Evita la fragmentación de herramientas. Ofrece escalado modular |
| New Relic | ✅ | ✅ | Flujos de trabajo sintéticos guionados. Fuerte observabilidad | Costoso. Tiene una curva de aprendizaje |
| Datadog | ✅ | ✅ | Vista completa desde UI, infraestructura, registros hasta métricas | Costoso a gran escala |
| Site24x7 | ✅ | ✅ | Todo en uno: web, servidor, red, nube, cobertura sintética & infra | La profundidad puede ser menor en algunos módulos |
| Pingdom | ✅ | – | Confiable en monitoreo de tiempo de actividad, transacciones & carga de página | Carece de verificaciones profundas de infraestructura & a nivel de protocolo |
| Checkly | ✅ | – | Guiones JS/Playwright para flujos de trabajo sintéticos | Requiere experiencia en scripting. No hay verificaciones de infra integradas |
| Zabbix | – | ✅ | Plataforma de alta versatilidad para entornos híbridos (SNMP, IPMI, JMX, & Agentes). | Gestión pesada en UI; escalar requiere un ajuste significativo de la base de datos. |
| Nagios | – | ✅ | Estabilidad legendaria para entornos estáticos/legados con una enorme biblioteca de plugins. | Alta “carga” de configuración; UI anticuada y carece de gráficos de series temporales nativos. |
| Prometheus | – | ✅ | El estándar CNCF para métricas nativas de K8s y etiquetado multidimensional. | Requiere almacenamiento externo (Thanos/Cortex) y herramientas adicionales para registros/sintéticos. |
| SolarWinds Network Performance Monitor (NPM) | – | ✅ | Excelente análisis de ruta de red, salto, nivel de dispositivo, SNMP, flujo | Menos enfoque en el monitoreo sintético |
| LogicMonitor, ManageEngine OpManager | – o Híbrido | ✅ | Monitoreo de infraestructura, red, sistemas con algunas características sintéticas o de integración | Monitoreo sintético débil, se requieren complementos. |
1. Dynatrace

Dynatrace es una solución que combina características como monitoreo sintético, monitoreo de usuarios reales, métricas de infraestructura y aplicación, y análisis automático de la causa raíz. Su arquitectura OneAgent recopila análisis a través de análisis contextual, IA y automatización.
Beneficios Clave
- Detección y análisis de anomalías impulsados por IA;
- Correlación de verificaciones sintéticas con trazas de infraestructura;
- Cobertura de pila completa, incluyendo monitoreo sintético global;
- Bueno para entornos híbridos, en la nube y complejos empresariales.
Mejor Para: Complejidad Empresarial Masiva & Causa Raíz Automatizada.
Escenario de la Vida Real: Tu banco está migrando un monolito legado a una arquitectura de microservicios híbridos en la nube. Una sola solicitud de “transferir dinero” ahora toca más de 50 servicios en AWS y un centro de datos local.
La Solución: Despliegas el OneAgent. Cuando la latencia de la transacción aumenta, la IA de Dynatrace (Davis) mapea automáticamente la topología y te dice: “El retraso no está en el código; es un bloqueo específico de la base de datos en el clúster SQL local que está causando una cascada.”
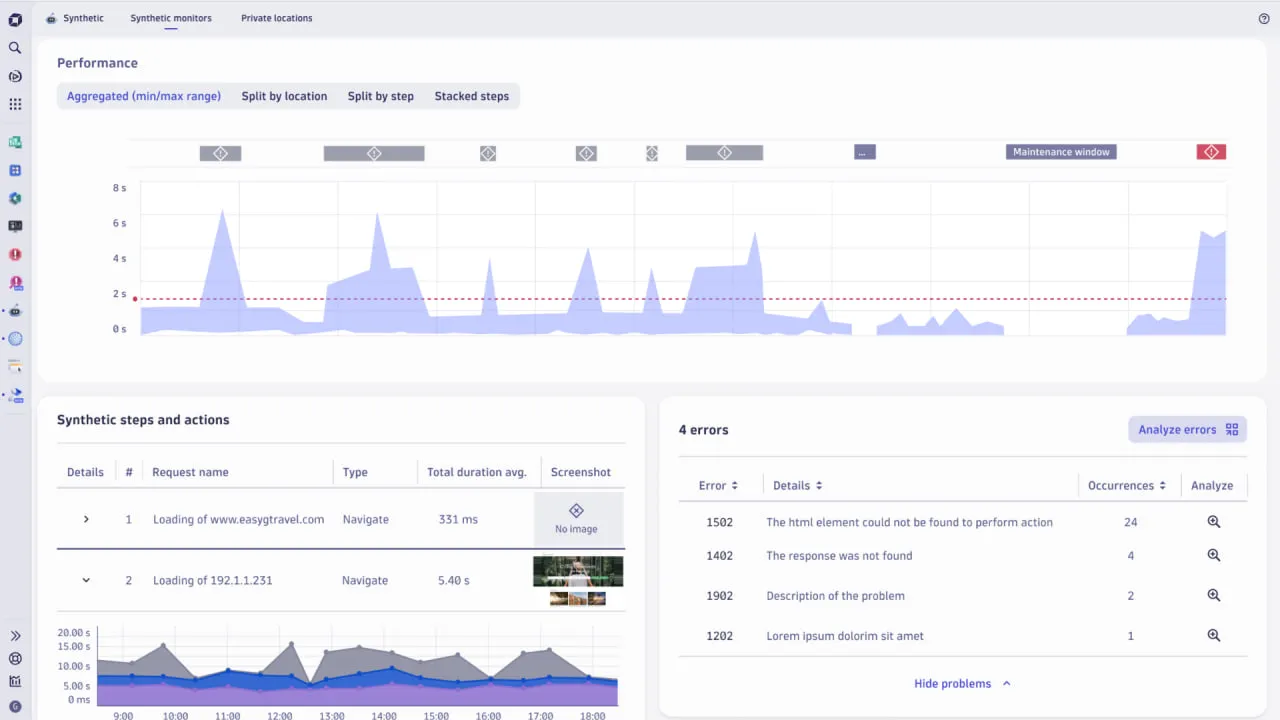
2. Dotcom‑Monitor

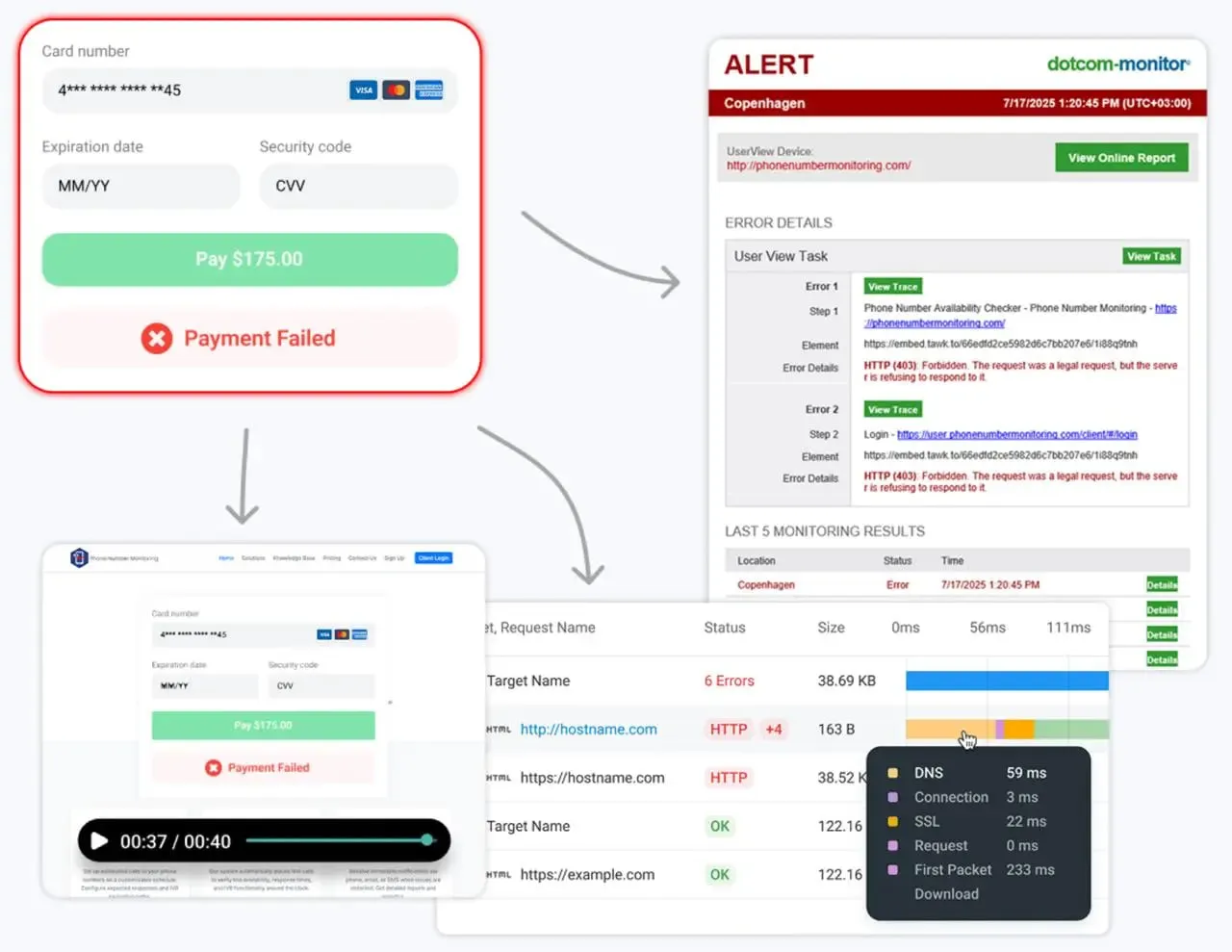
Dotcom-Monitor es una plataforma unificada que ofrece tanto monitoreo sintético (rendimiento web, flujos guionados, verificaciones de API) como monitoreo de infraestructura (DNS, FTP, ICMP, verificaciones de puertos TCP, VoIP). También integra el monitoreo de servidores y dispositivos a través de su módulo ServerView para una visibilidad completa con solo una interfaz.
Beneficios Clave
- Encuentra anomalías subyacentes al estimular interacciones de usuario;
- Verificaciones multi-ubicación para mejorar la experiencia del usuario y la infraestructura;
- Todo bajo un panel unificado sin cambiar de herramientas;
- Enfoque modular: habilita módulos de infraestructura según sea necesario;
- Reduce la sobrecarga operativa, como la gestión de múltiples herramientas.
Mejor Para: Experiencia del Usuario Global & Fiabilidad Multi-Protocolo.
Escenario de la Vida Real: Administra una plataforma de comercio electrónico de alto tráfico con una base de clientes global. Has tenido varios incidentes donde el sitio estaba “activo” según las métricas internas, pero los clientes en Europa no podían completar las compras debido a la latencia regional de DNS o un tiempo de espera de un gateway de pago de terceros.
La Solución: Usas Dotcom-Monitor para ejecutar flujos sintéticos en un navegador real desde más de 30 ubicaciones globales cada 5 minutos. Cuando un ISP regional en Londres tiene un problema de enrutamiento, recibes una alerta con un gráfico de cascada que muestra el error exacto 404 o 500 antes de que tu mesa de ayuda se inunde con tickets.
3. New Relic

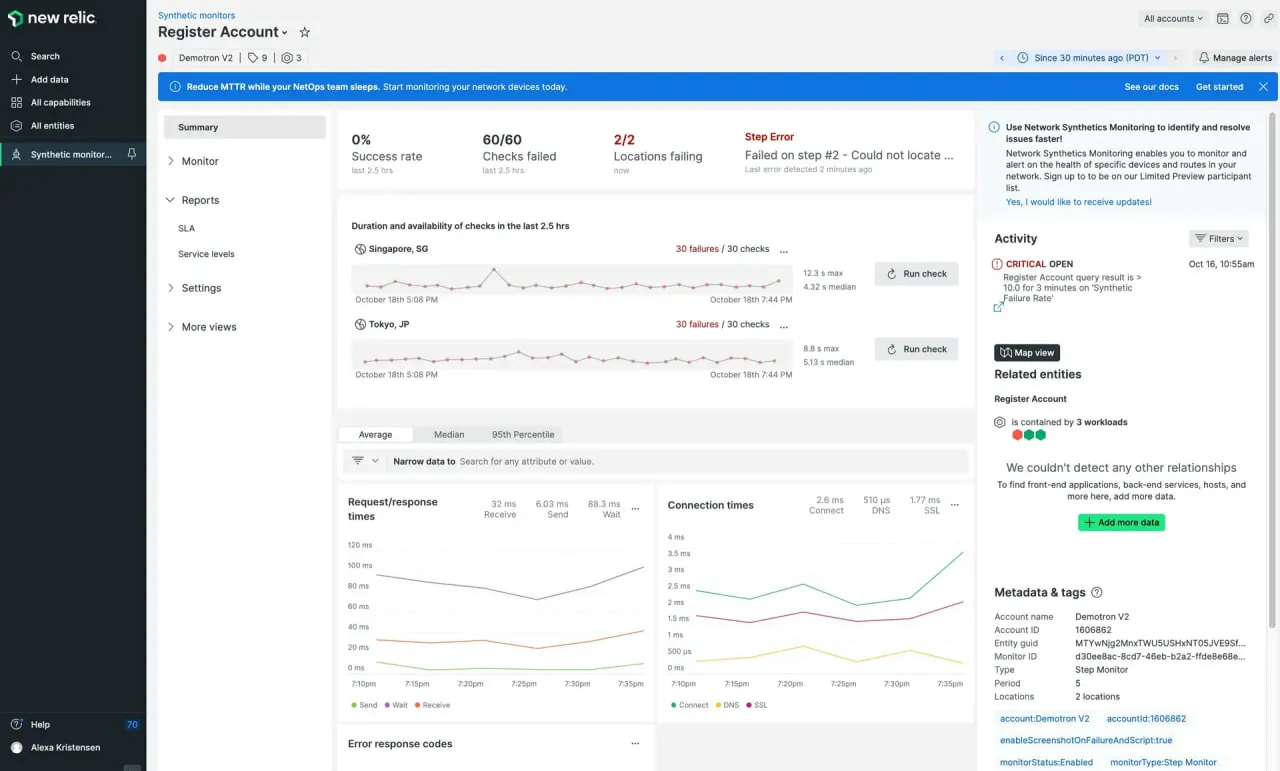
New Relic te permite escribir scripts de flujo de trabajo de navegador y API, y luego vincular esos resultados a su pila de observabilidad (APM, infraestructura, registros). Está diseñado para equipos que quieren todo en un solo ecosistema.
Beneficios Clave
- Rica flexibilidad de scripting para flujos de usuario complejos;
- Fuerte integración con métricas y registros de backend;
- Paneles unificados y sistema de alertas;
- Buen soporte y ecosistema.
Mejor Para: Depuración Profunda de Aplicaciones & Optimización a Nivel de Código.
Escenario de la Vida Real: Después de un importante despliegue el viernes por la tarde, el tiempo de respuesta de tu API se duplica. Los registros muestran que todo está “OK”, pero los usuarios se quejan.
La Solución: Usas New Relic APM para profundizar en un “Rastro de Transacción”. Revela que una nueva expresión regular en la línea 402 de tu controlador de Python está causando picos de CPU, permitiéndote revertir y corregir la línea de código específica en minutos.
4. Datadog

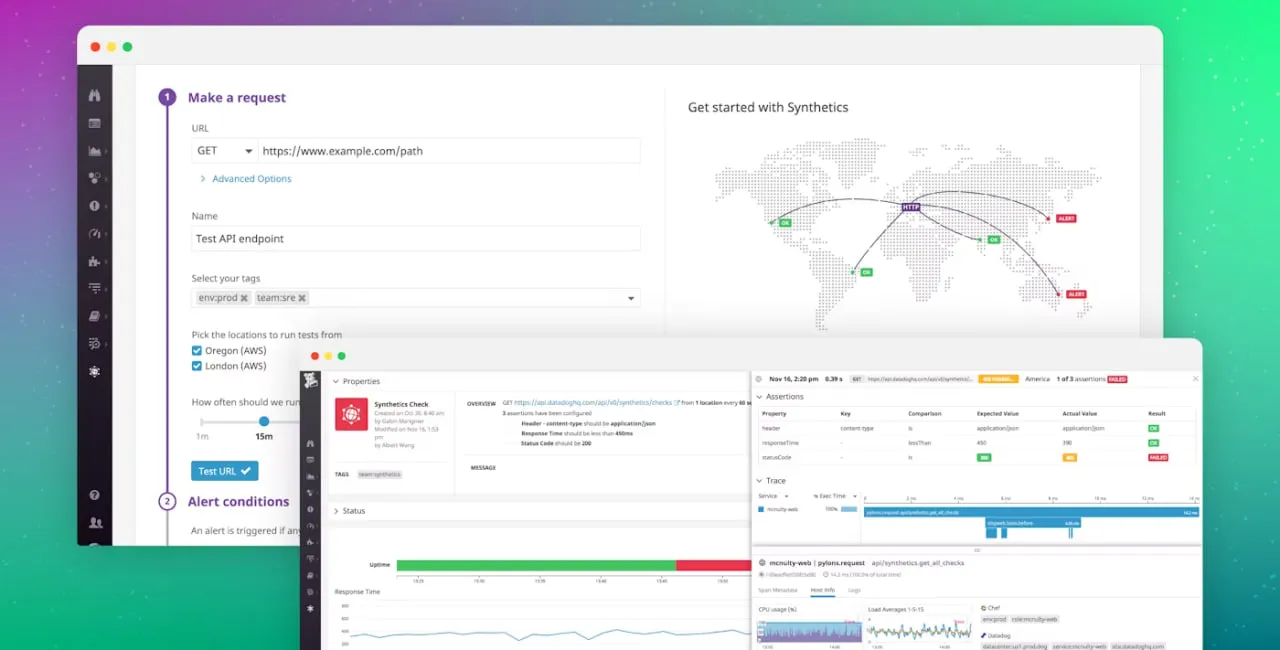
Datadog tiene un enfoque integrador que combina monitoreo sintético con recopilación de métricas, registros, trazado y salud de infraestructura. Así que esto te proporciona una solución todo en uno.
Beneficios Clave
- Correlación unificada entre sintético, infraestructura y registros;
- Panel y visualizaciones personalizadas;
- Amplias integraciones a través de servicios en la nube, contenedores, bases de datos, etc.;
- Se puede escalar para sistemas grandes.
Mejor Para: Equipos Nativos en la Nube de Alta Velocidad.
Escenario de la Vida Real: Administra una flota de más de 500 microservicios de Kubernetes que escalan hacia arriba y hacia abajo 20 veces al día. Necesitas saber si un despliegue específico de “Canary” está causando errores en un servicio descendente.
La Solución: Usas Mapas de Servicio y Correlación de Registros. Cuando un pod se bloquea, haces clic en el error en tu panel y ves instantáneamente los registros y trazas específicos para ese contenedor exacto, filtrados por la etiqueta “versión”.
5. Site24x7

Site24x7 cubre flujos de usuarios sintéticos, monitoreo de servidores y redes, infraestructura en la nube, aplicaciones y más. Para equipos pequeños y medianos, esta es una buena herramienta que ofrece cobertura completa.
Beneficios Clave
- Monitoreo para web, servidor, red, aplicaciones;
- Soporte de protocolo de infraestructura;
- Aprendizaje fácil y paso a paso;
- Precios flexibles y buena relación calidad-precio.
Mejor Para: Equipos Conscientes del Presupuesto que Necesitan lo Básico “Todo en Uno”.
Escenario de la Vida Real: Eres el único ingeniero de DevOps en una startup de 50 personas. Necesitas monitorear tu sitio web, el enrutador VPN de tu oficina y tu factura de AWS con un presupuesto limitado.
La Solución: Usas Site24x7 para configurar pings básicos de tiempo de actividad y un Agente de Servidor en tus máquinas Linux. Es una herramienta de “configurar y olvidar” que te brinda el 80% de la visibilidad de herramientas costosas al 20% del costo.
6. Pingdom

Pingdom es una herramienta de monitoreo sintético basada en la web. Sus características incluyen mediciones de carga de página y simulaciones de viaje del usuario desde múltiples ubicaciones. Es una excelente opción para cualquiera que se enfoque en el monitoreo web.
Beneficios Clave
- Configuración y despliegue rápidos;
- Verificaciones de múltiples ubicaciones para la detección de problemas regionales;
- Soporte para monitoreo de múltiples pasos;
- Alertas en tiempo real e informes de rendimiento.
Mejor Para: Marketing & Partes Interesadas Empresariales.
Escenario de la Vida Real: Tu CMO quiere una simple “Página de Estado Pública” para mostrar a los clientes que el sitio es confiable.
La Solución: Configuras un simple Pingdom Check. Es de bajo costo y alta fiabilidad. Cuando el sitio se cae, activa una actualización de “Página de Estado” que mantiene informados a tus usuarios sin exponer tus complejos paneles internos de SRE.
7. Checkly

Checkly es para desarrolladores ya que enfatiza el scripting en JavaScript y Playwright para definir verificaciones. Esto lo hace ideal para personas que saben programar.
Beneficios Clave
- Verificaciones sintéticas altamente personalizables a través de código;
- Se integra fácilmente en pipelines de CI/CD;
- Bueno para monitoreo de API y basado en navegador;
- Interfaz moderna y ligera orientada a herramientas para desarrolladores.
Mejor Para: Frontend Moderno & Ingeniería de QA (Primero Playwright).
Escenario de la Vida Real: Tu equipo se está moviendo hacia un modelo de “Tú lo construyes, tú lo ejecutas”. Tus desarrolladores ya usan Playwright para pruebas locales y quieren usar esos mismos scripts para monitorear producción.
La Solución: Integras Checkly en tus Acciones de GitHub. Cada vez que se fusiona un PR, Checkly actualiza automáticamente tus monitores de “Latido” de producción utilizando el mismo código que tus desarrolladores escribieron para las pruebas.
8. Prometheus
Prometheus es el “estándar de oro” graduado por CNCF para monitoreo nativo en la nube. Pionero en el modelo de métricas basado en pull y el uso de etiquetas multidimensionales, que son esenciales para rastrear pods efímeros de Kubernetes.
Beneficios Clave
- Auto-descubrimiento sin problemas para servicios y contenedores de Kubernetes.
- Un poderoso lenguaje de consulta diseñado para operaciones pesadas en matemáticas (por ejemplo, calcular la latencia del percentil 99).
- Cada servidor es autónomo sin dependencia de bases de datos externas, lo que lo hace resistente durante cortes.
Mejor Para: Auto-escalado de Kubernetes & Microservicios.
Escenario de la Vida Real: Estás ejecutando una API de retail en EKS (Amazon Kubernetes Service). Durante una “Venta Flash”, tu HPA (Horizontal Pod Autoscaler) inicia 200 nuevos pods.
La Solución: Prometheus descubre automáticamente estos pods a través de la API de Kubernetes, recopila sus métricas al instante y te alerta si la latencia p99 en toda la flota excede los 200 ms, sin que tú tengas que agregar manualmente una sola dirección IP a un archivo de configuración.
9. Zabbix
Zabbix es la “navaja suiza” del monitoreo de infraestructura. Es una plataforma centralizada, lista para empresas, que sobresale en el monitoreo de “estados mixtos”, donde tienes una mezcla de servidores Linux modernos, cajas Windows legadas y equipos de red físicos.
Beneficios Clave
- Zabbix incluye paneles, alertas e informes en una sola interfaz web nativa.
- Soporte de primera clase para hardware físico (enrutadores, conmutadores e incluso termómetros de sala de servidores).
- Si puedes escribir un script para ello (Python, Bash, Go), Zabbix puede monitorearlo.
Mejor Para: Infraestructura Híbrida & Estados de Red Diversos.
Escenario de la Vida Real: Administra una red universitaria. Necesitas monitorear 500 Máquinas Virtuales, 200 Conmutadores Cisco y la temperatura de tres centros de datos diferentes.
La Solución: Usas Zabbix con Agentes Activos para las VMs y SNMP para los conmutadores. Construyes un “Mapa de Red” en la UI de Zabbix que se vuelve rojo si un conmutador central se cae, permitiéndote ver exactamente qué servidores están aislados por la falla de hardware.
10. Nagios (Core & XI)
El “Abuelo” del monitoreo. Nagios se basa en una simple arquitectura de “Plugin”: ejecuta un script, observa el código de salida (0, 1, 2) y alerta en consecuencia. Es legendario por su estabilidad, pero criticado por su interfaz de la década de 1990 y la fricción de configuración.
Beneficios Clave
- Si existe en un centro de datos, alguien ya ha escrito un plugin de Nagios para ello en los últimos 25 años.
- El motor central es increíblemente ligero y puede ejecutarse en hardware mínimo.
- Sigue un flujo simple de “Verificación -> Resultado -> Alerta” que es fácil de solucionar.
Mejor Para: Entornos Estables, Legados o “Estáticos”.
Escenario de la Vida Real: Administra una serie de servidores “Air-Gapped” críticos en una instalación segura. Estos servidores nunca cambian, no se escalan automáticamente y deben permanecer activos 24/7/365.
La Solución: Usas Nagios Core. Es sólido como una roca y no se romperá durante una actualización. Usas un simple plugin check_disk y check_ssh. Envía un solo correo electrónico confiable en el momento en que falla un raid de hardware, y lo hace sin dependencias de “SaaS” o en la nube.
11. SolarWinds NPM

SolarWinds Network Performance Monitor (NPM) se especializa en monitoreo de dispositivos de red y nivel de ruta. Rastrea la accesibilidad, latencia de salto, salud del dispositivo, tráfico de interfaz, métricas SNMP y topología de red.
Beneficios Clave
- Visibilidad excepcional de ruta de red, salto e interfaz;
- Soporte de SNMP y NetFlow, métricas a nivel de dispositivo;
- Perspectivas sobre cuellos de botella de red y problemas de topología;
- Fuertes diagnósticos para interrupciones relacionadas con la red.
Mejor Para: Administradores de Red & Infraestructura Física.
Escenario de la Vida Real: Los usuarios se quejan de que “el internet es lento”. Sospechas de un problema de hardware en la sala de servidores o un mal salto de fibra entre tus oficinas.
La Solución: Usas NetPath. Te muestra un mapa salto a salto de la ruta de red. Ves un pico de latencia de 200 ms en un enrutador Cisco específico en tu sucursal de Dallas, confirmando que es un cuello de botella de hardware, no un error de software.
12. LogicMonitor / ManageEngine OpManager
 LogicMonitor y ManageEngine son herramientas para monitorear infraestructura a nivel empresarial, con módulos sintéticos e integraciones de experiencia del usuario. Son buenas para monitoreo de dispositivos, servidores, VM y aplicaciones.
LogicMonitor y ManageEngine son herramientas para monitorear infraestructura a nivel empresarial, con módulos sintéticos e integraciones de experiencia del usuario. Son buenas para monitoreo de dispositivos, servidores, VM y aplicaciones.
Beneficios Clave
- Amplia infraestructura de servidores, red y aplicaciones;
- Conveniencia de integración y automatización preconstruidas;
- Panel perfecto para operaciones empresariales;
- Algunas opciones para integración de módulos sintéticos.
Mejor Para: IT Híbrido & Proveedores de Servicios Gestionados (MSPs).
Escenario de la Vida Real: Administra IT para una empresa con 10 oficinas globales, cada una con sus propios servidores locales, almacenamiento NetApp y clústeres de VMware, todos conectados a Azure.
La Solución: Usas la arquitectura Collector de LogicMonitor. Descubre automáticamente todos los 2,000+ dispositivos en tu red y construye un “Panel Empresarial” que muestra la salud de tu almacenamiento físico, máquinas virtuales e instancias en la nube en una sola vista.
¿Cómo Elegir Tu Pila de Monitoreo?
Seleccionar un conjunto de monitoreo se trata menos de “encontrar la mejor herramienta” y más de minimizar la brecha entre un incidente y su resolución. Para un equipo moderno de DevOps o SRE, el proceso de toma de decisiones debe priorizar lo siguiente:
1. Evaluar Cobertura vs. Dispersión de Herramientas
Pregunta si tu equipo puede gestionar realísticamente una pila “mejor de su clase” (por ejemplo, Prometheus para métricas, Checkly para scripts y SolarWinds para red). Si bien es especializado, esto a menudo conduce a “silos de datos”. Plataformas unificadas como Dotcom-Monitor o Datadog reducen el cambio de contexto durante cortes de alta presión al correlacionar fallas sintéticas directamente con la salud de la infraestructura.
2. Priorizar Automatización y Soporte de IaC
En un entorno nativo de la nube, la configuración manual es una responsabilidad. Asegúrate de que la herramienta elegida soporte Terraform, Pulumi o una CLI integral. Si no puedes provisionar una verificación sintética como parte de un despliegue de servicio, la herramienta eventualmente se convertirá en un cuello de botella para tu velocidad de ingeniería.
3. Evaluar la Relación Señal-Ruido
La mayor amenaza para un SRE es la fatiga de alertas. Busca herramientas que ofrezcan lógica de alertas sofisticada, como “X fallas de Y ubicaciones” para filtrar los parpadeos transitorios de la red. Evita plataformas que imponen un umbral “talla única”, que a menudo conduce a “gritar lobo” y notificaciones ignoradas.
4. Analizar el Costo Total de Propiedad (TCO)
Más allá del precio de etiqueta, considera la sobrecarga operativa. Soluciones de código abierto como Zabbix o Prometheus son “gratuitas” en licencias pero costosas en horas de ingeniería requeridas para mantenimiento, parches y escalado. Las plataformas SaaS intercambian costos de licencia más altos por una “carga” reducida, permitiendo que tu equipo se enfoque en la fiabilidad del sitio en lugar del mantenimiento del servidor de monitoreo.
Muchos equipos adoptan una pila en capas o se lanzan por completo a plataformas unificadas como Dotcom‑Monitor. Lo que es mejor para ti depende de tu presupuesto, sistema, tamaño del equipo y experiencia del equipo.
Conclusión
En 2026, la “mejor” herramienta es la que elimina los silos entre tus equipos de DevOps, SRE y QA. Si estás gestionando un entorno complejo y nativo de la nube, Datadog o Dynatrace ofrecen una correlación inigualable, aunque a un precio premium. Para equipos que buscan un enfoque robusto y unificado que combine verificaciones de protocolo profundas con transacciones sintéticas globales sin el “impuesto empresarial”, Dotcom-Monitor ofrece el equilibrio más pragmático de visibilidad “externa” e “interna”.
En última instancia, tu objetivo debe ser tratar el Monitoreo como Código. Prioriza herramientas con un fuerte soporte de API y proveedores de Terraform para que tu monitoreo evolucione tan rápido como tu infraestructura.
Frequently Asked Questions
- Usa alertas a través de un sistema central
- Usa niveles de severidad y umbrales sabiamente
- Suprime durante las ventanas de mantenimiento
- Agrupa alertas relacionadas y filtra duplicados
- Ajusta según los falsos positivos históricos