选择合适的基础设施和合成监控工具不再仅仅是为了勾选正常运行时间的框;而是为了缩小后端健康状况与实际终端用户体验之间的可见性差距。在现代DevOps环境中,DNS路由的故障或延迟的第三方API可能与服务器崩溃一样具有灾难性,但这些“外部问题”往往被传统内部监控所忽视。
本指南评估了12种最佳基础设施和合成监控工具,特别为需要减少MTTR(平均修复时间)并消除生产堆栈中的“盲点”的技术团队精心策划。
合成监控与基础设施监控
虽然合成监控从全球位置验证功能工作流,但基础设施监控提供了诊断导致这些工作流失败的硬件和网络故障所需的详细遥测。
| 监控类型 | 功能 | 关键用例与优势 |
| 合成监控 | 模拟用户操作、脚本化工作流和定期API调用 | 捕捉断开的流程和延迟。跨位置基准测试。正常运行时间/交易健康 |
| 基础设施监控 | 跟踪:服务器、网络设备、服务(DNS、TCP/UDP、ping等)和资源指标 | 检测:后端和协议级故障、服务中断和资源饱和 |
比较12种最佳基础设施和合成监控工具
| 工具 | 合成 | 基础设施 | 亮点 | 权衡 |
| Dynatrace | ✅ | ✅ | AI驱动的可观察性,连接用户流程和后端指标 | 复杂。成本可能迅速增加 |
| Dotcom-Monitor | ✅ | ✅ | 一个平台上的合成和服务监控 | 避免工具碎片化。提供模块化扩展 |
| New Relic | ✅ | ✅ | 脚本化合成工作流。强大的可观察性 | 价格昂贵。学习曲线陡峭 |
| Datadog | ✅ | ✅ | 从UI、基础设施、日志到指标的全视图 | 大规模时成本高昂 |
| Site24x7 | ✅ | ✅ | 一体化:网络、服务器、网络、云、合成和基础设施覆盖 | 某些模块的深度可能较低 |
| Pingdom | ✅ | – | 在正常运行时间、交易和页面加载监控中可靠 | 缺乏深入的基础设施和协议级检查 |
| Checkly | ✅ | – | 用于合成工作流的JS/Playwright脚本 | 需要脚本专业知识。没有内置的基础设施检查 |
| Zabbix | – | ✅ | 高灵活性的混合环境平台(SNMP、IPMI、JMX和代理)。 | 以UI为主的管理;扩展需要显著的数据库调整。 |
| Nagios | – | ✅ | 在静态/遗留环境中具有传奇的稳定性,拥有庞大的插件库。 | 高配置“劳作”;过时的UI且缺乏本地时间序列图形。 |
| Prometheus | – | ✅ | CNCF标准的K8s原生指标和多维标签。 | 需要外部存储(Thanos/Cortex)和额外的日志/合成工具。 |
| SolarWinds网络性能监控(NPM) | – | ✅ | 出色的网络路径、跳数、设备级、SNMP、流量分析 | 对合成监控关注较少 |
| LogicMonitor,ManageEngine OpManager | –或混合 | ✅ | 基础设施、网络、系统监控,具有一些合成或集成功能 | 合成监控较弱,需要附加组件。 |
1. Dynatrace

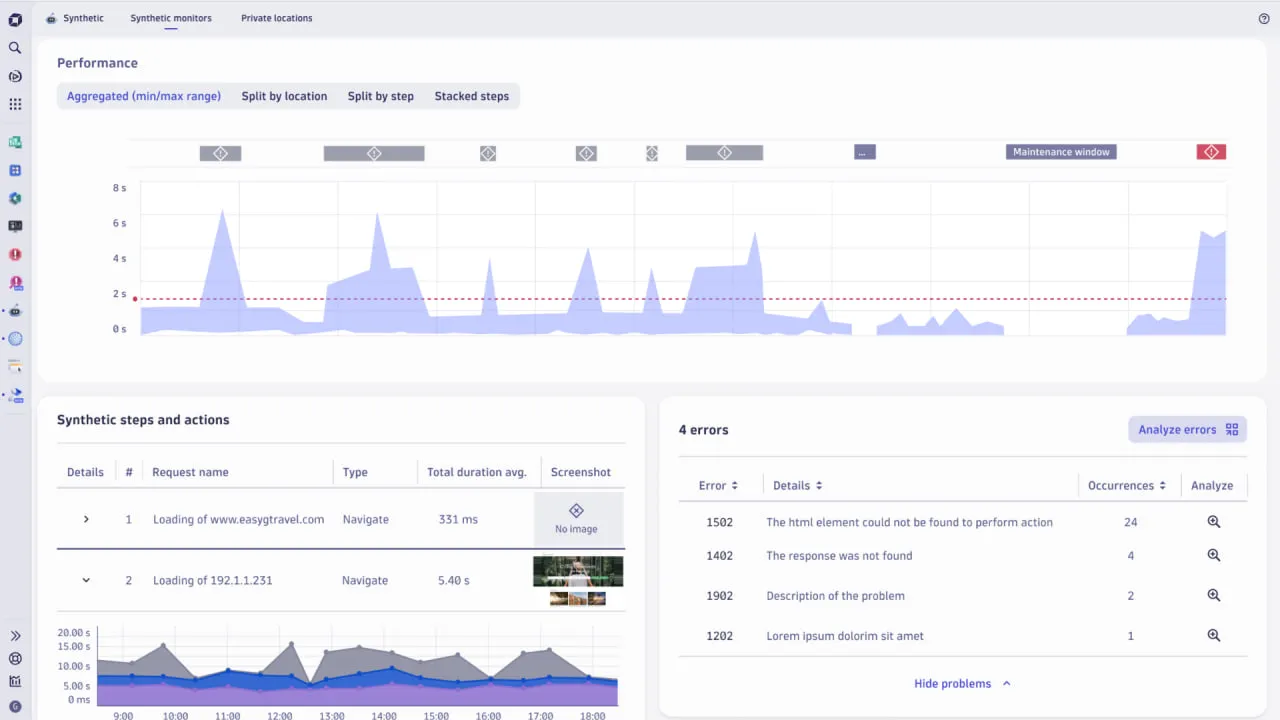 Dynatrace是一个结合了合成监控、真实用户监控、基础设施和应用指标以及自动根本原因分析等功能的解决方案。其OneAgent架构通过上下文分析、AI和自动化收集分析数据。
Dynatrace是一个结合了合成监控、真实用户监控、基础设施和应用指标以及自动根本原因分析等功能的解决方案。其OneAgent架构通过上下文分析、AI和自动化收集分析数据。
关键优势
- AI驱动的异常检测和分析;
- 合成检查与基础设施跟踪的关联;
- 全栈覆盖,包括全球合成监控;
- 适合混合、云和复杂的企业环境。
最佳适用:巨大的企业复杂性和自动根本原因。真实场景:您的银行正在将遗留单体迁移到混合云微服务架构。单个“转账”请求现在涉及50多个服务,跨越AWS和本地数据中心。解决方案:您部署OneAgent。当交易延迟激增时,Dynatrace的AI(Davis)会自动映射拓扑并告诉您:“延迟不在代码中;这是本地SQL集群中的特定数据库锁导致的级联。”
2. Dotcom‑Monitor

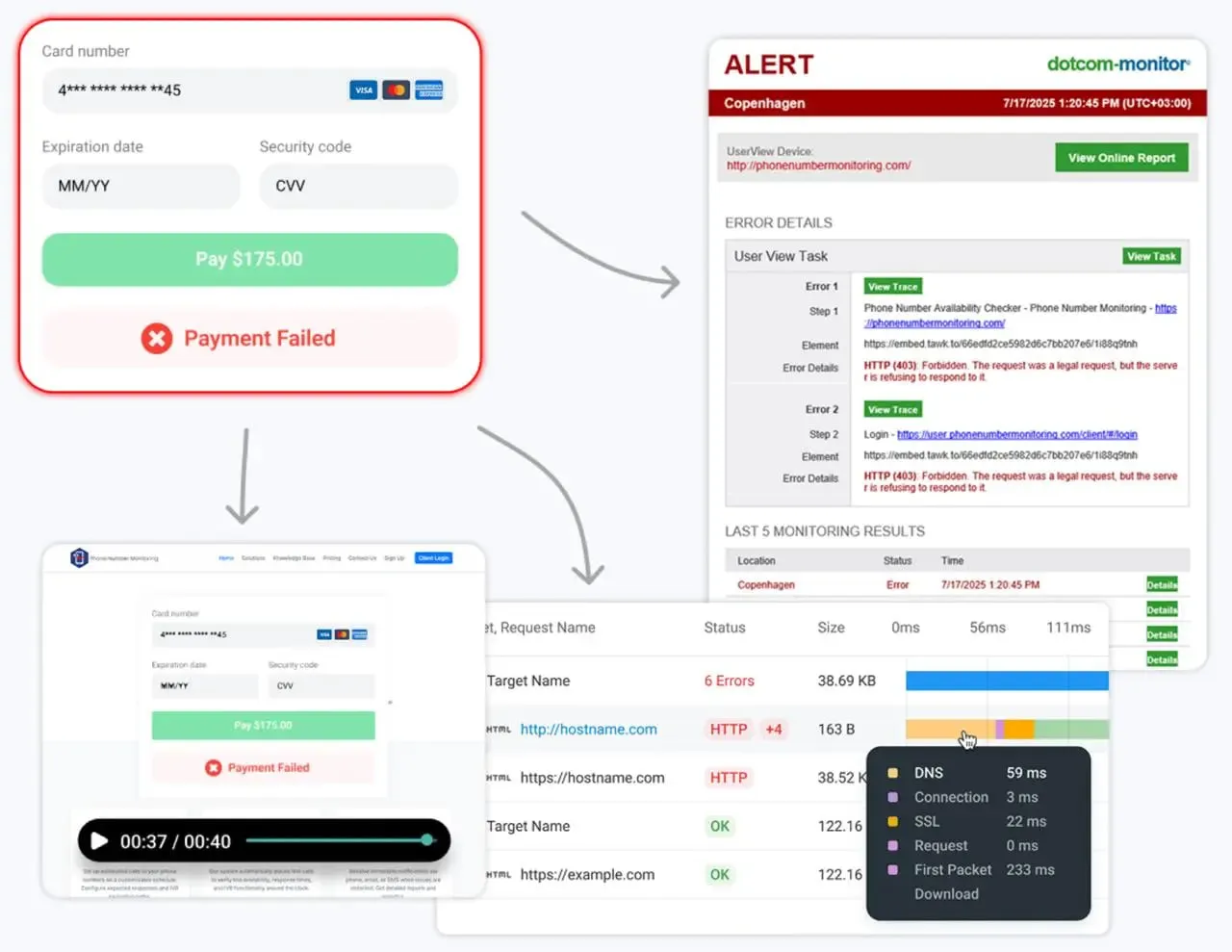 Dotcom-Monitor是一个统一的平台,提供合成监控(网络性能、脚本化流程、API检查)和基础设施监控(DNS、FTP、ICMP、UDP、TCP端口检查、VoIP)。它还通过其ServerView模块集成服务器和设备监控,提供仅需一个界面的完整可见性。
Dotcom-Monitor是一个统一的平台,提供合成监控(网络性能、脚本化流程、API检查)和基础设施监控(DNS、FTP、ICMP、UDP、TCP端口检查、VoIP)。它还通过其ServerView模块集成服务器和设备监控,提供仅需一个界面的完整可见性。
关键优势
- 通过刺激用户交互发现潜在异常;
- 多位置检查以改善用户体验和基础设施;
- 在一个统一的仪表板下,无需切换工具;
- 模块化方法——根据需要启用基础设施模块;
- 减少操作开销,例如管理多个工具。
最佳适用:全球用户体验和多协议可靠性。真实场景:您运营一个高流量的电子商务平台,拥有全球客户群。您遇到过几次事件,网站根据内部指标显示“正常”,但欧洲的客户由于区域DNS延迟或第三方支付网关超时而无法完成结账。解决方案:您使用Dotcom-Monitor每5分钟从30多个全球位置运行真实浏览器合成流程。当伦敦的一个区域ISP出现路由问题时,您会收到警报,并附有瀑布图,显示确切的404或500错误,避免您的帮助台被工单淹没。
3. New Relic

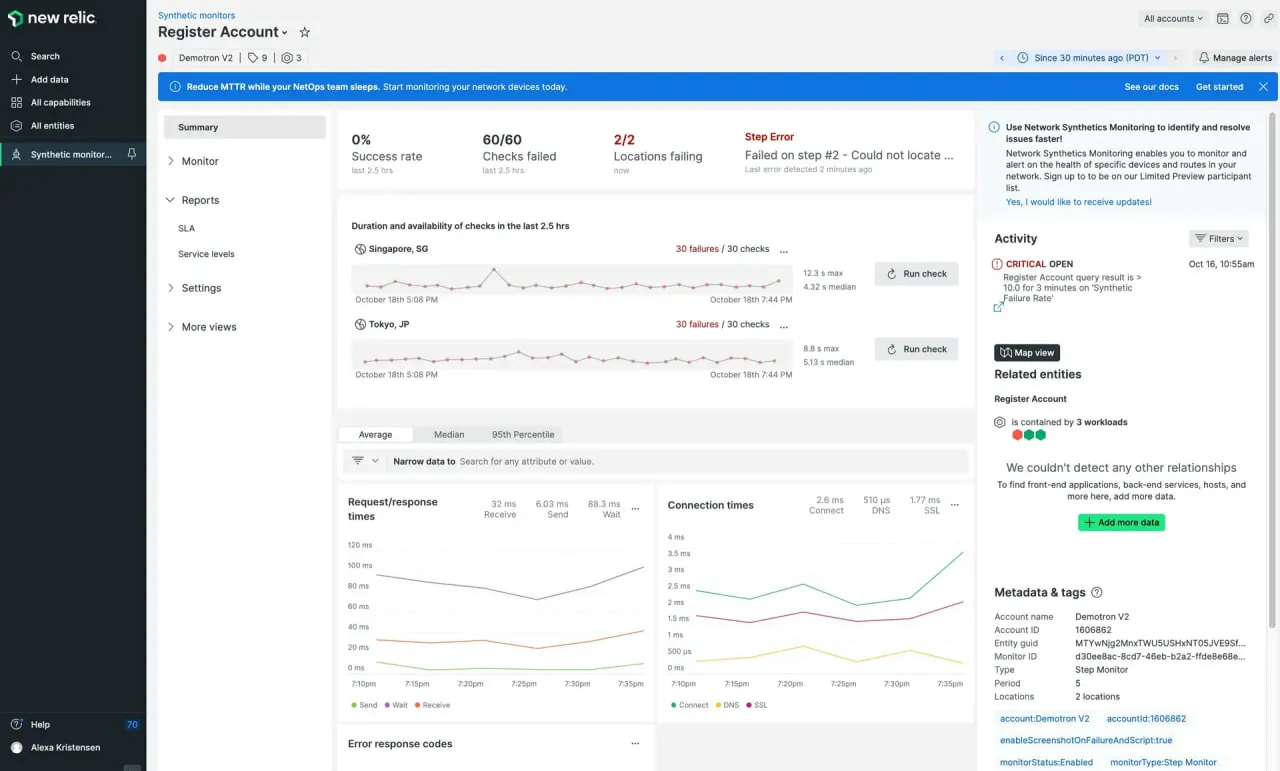 New Relic允许您编写浏览器和API工作流脚本,然后将这些结果与其可观察性堆栈(APM、基础设施、日志)结合。它旨在为希望将所有内容整合到一个生态系统中的团队提供服务。
New Relic允许您编写浏览器和API工作流脚本,然后将这些结果与其可观察性堆栈(APM、基础设施、日志)结合。它旨在为希望将所有内容整合到一个生态系统中的团队提供服务。
关键优势
- 复杂用户流程的丰富脚本灵活性;
- 与后端指标和日志的强大集成;
- 统一的仪表板和警报系统;
- 良好的支持和生态系统。
最佳适用:深度应用调试和代码级优化。真实场景:在一次重大的周五下午部署后,您的API响应时间翻倍。日志显示一切“正常”,但用户抱怨。解决方案:您使用New Relic APM深入分析“事务跟踪”。它揭示了您Python控制器第402行中的一个新正则表达式导致CPU峰值——让您能够在几分钟内恢复并修复特定的代码行。
4. Datadog

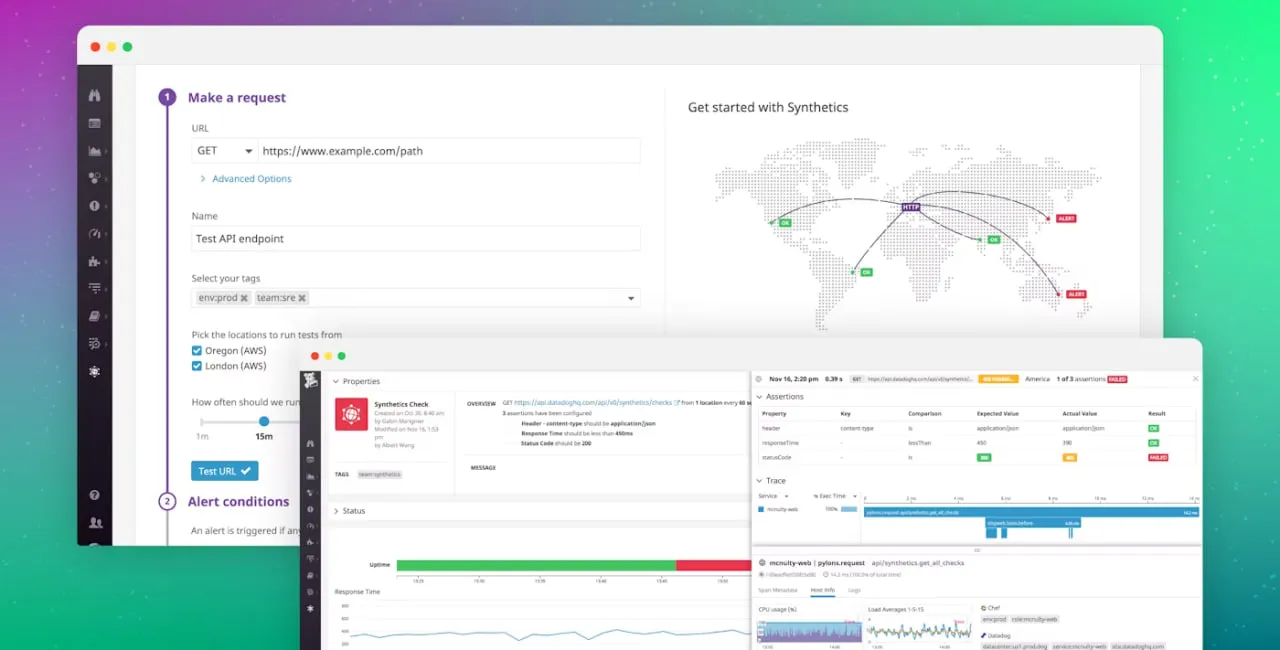 Datadog采用集成的方法,将合成监控与指标收集、日志、跟踪和基础设施健康结合在一起。因此,这在某种程度上为您提供了一种一体化解决方案。
Datadog采用集成的方法,将合成监控与指标收集、日志、跟踪和基础设施健康结合在一起。因此,这在某种程度上为您提供了一种一体化解决方案。
关键优势
- 合成、基础设施和日志之间的统一关联;
- 自定义仪表板和可视化;
- 广泛的云服务、容器、数据库等集成;
- 可扩展以适应大型系统。
最佳适用:高速度的云原生团队。真实场景:您管理着500多个Kubernetes微服务,每天上下扩展20次。您需要知道特定的“金丝雀”部署是否在下游服务中引发错误。解决方案:您使用服务地图和日志关联。当一个pod崩溃时,您在仪表板中单击错误,即可立即查看该特定容器的具体日志和跟踪,按“版本”标签过滤。
5. Site24x7

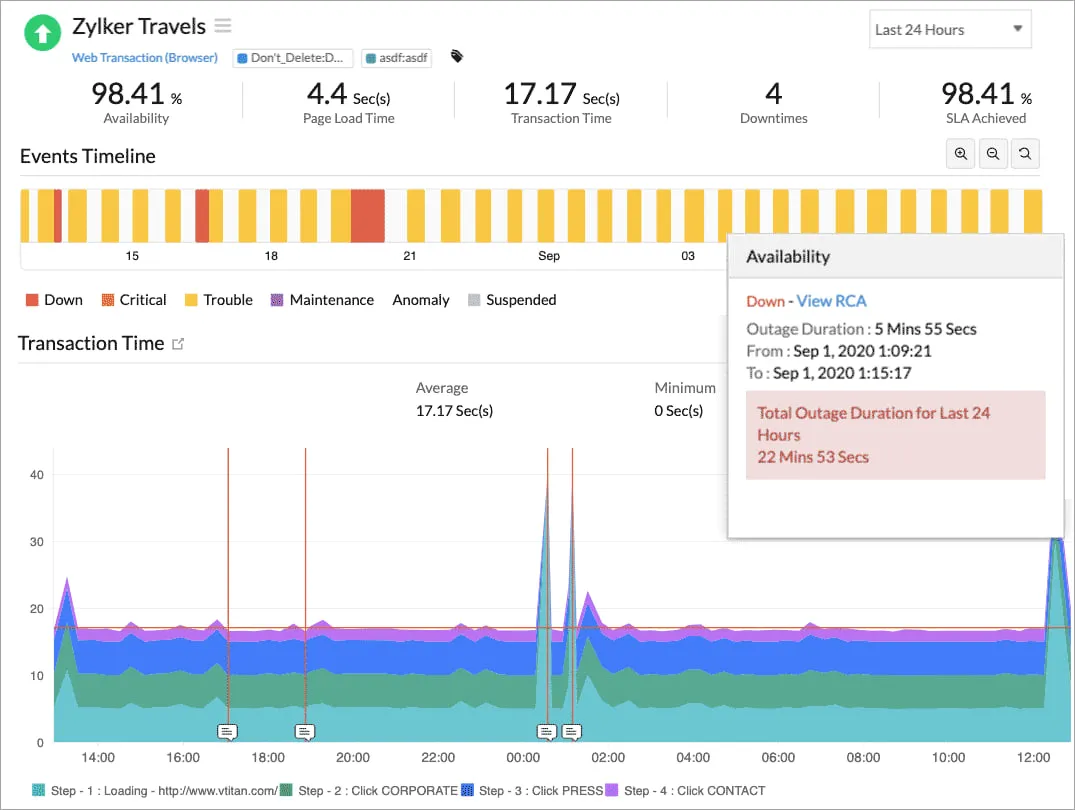 Site24x7涵盖合成用户流程、服务器和网络监控、云基础设施、应用程序等。对于小型和中型团队来说,这是一个提供全面覆盖的良好工具。
Site24x7涵盖合成用户流程、服务器和网络监控、云基础设施、应用程序等。对于小型和中型团队来说,这是一个提供全面覆盖的良好工具。
关键优势
- 监控网络、服务器、网络、应用程序;
- 基础设施协议支持;
- 简单且逐步学习;
- 灵活的定价和良好的性价比。
最佳适用:预算有限的团队需要“全能”基础。真实场景:您是一个50人初创公司的唯一DevOps工程师。您需要在有限的预算内监控您的网站、办公室的VPN路由器和AWS账单。解决方案:您使用Site24x7设置基本的正常运行时间ping和在Linux机器上运行的服务器代理。这是一个“设置后忘记”的工具,可以以20%的成本提供80%的可见性。
6. Pingdom

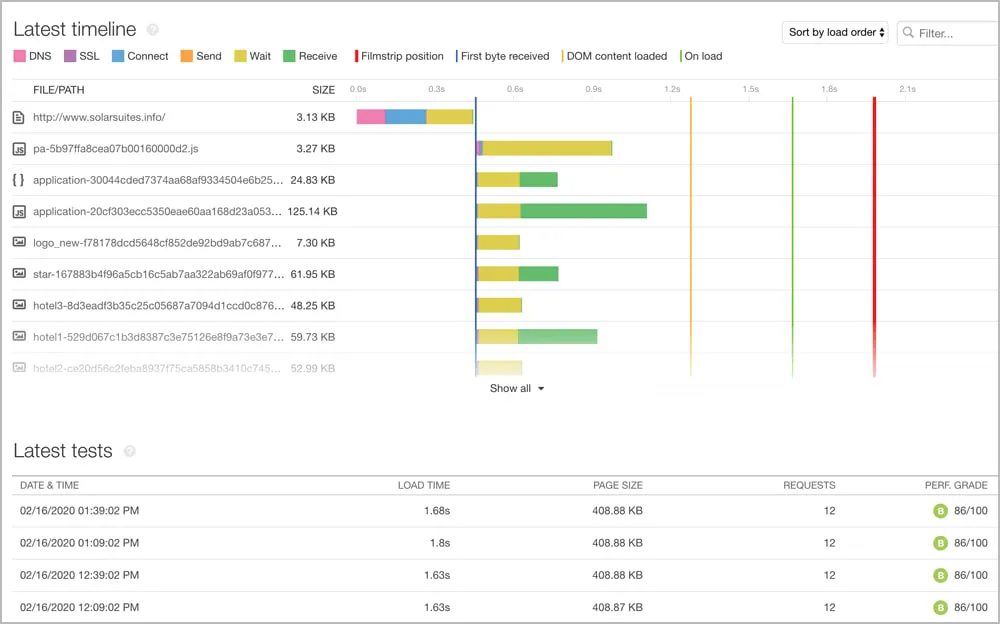 Pingdom是一个基于Web的合成监控工具。其功能包括页面加载测量和来自多个位置的用户旅程模拟。对于任何专注于网络监控的人来说,这是一个很好的选择。
Pingdom是一个基于Web的合成监控工具。其功能包括页面加载测量和来自多个位置的用户旅程模拟。对于任何专注于网络监控的人来说,这是一个很好的选择。
关键优势
- 快速配置和部署;
- 多个位置检查以检测区域问题;
- 多步骤监控支持;
- 实时警报和性能报告。
最佳适用:市场营销和业务利益相关者。真实场景:您的CMO希望有一个简单的“公共状态页面”来向客户展示网站的可靠性。解决方案:您设置了一个简单的Pingdom检查。它成本低且可靠性高。当网站宕机时,它会触发“状态页面”更新,让您的用户保持知情,而不暴露您内部复杂的SRE仪表板。
7. Checkly

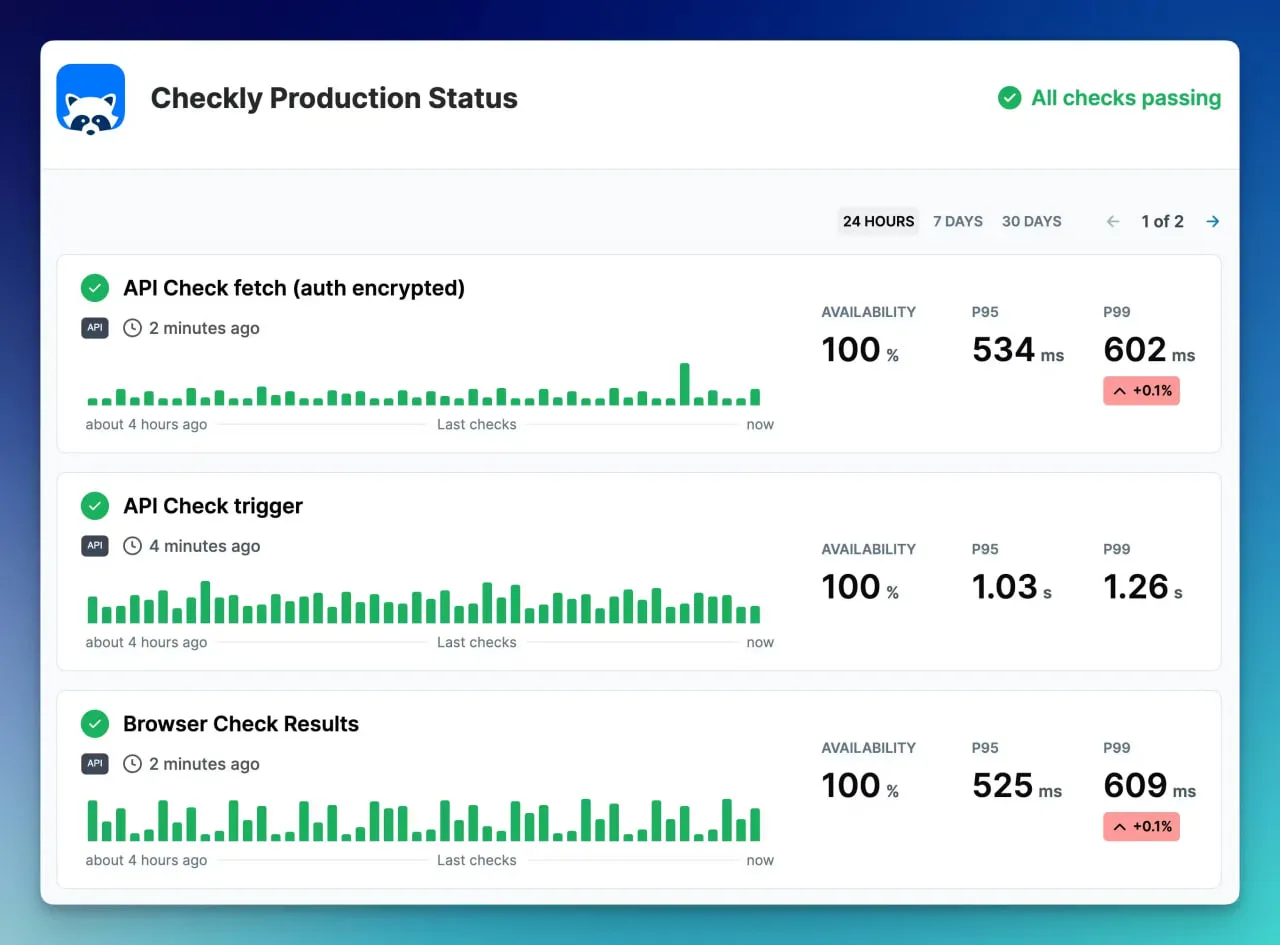 Checkly是为开发人员设计的,因为它强调JavaScript和Playwright脚本来定义检查。这使其非常适合懂得编码的人。
Checkly是为开发人员设计的,因为它强调JavaScript和Playwright脚本来定义检查。这使其非常适合懂得编码的人。
关键优势
- 通过代码高度可定制的合成检查;
- 轻松集成到CI/CD管道中;
- 适合API和基于浏览器的监控;
- 轻量级、现代UI和开发者工具导向。
最佳适用:现代前端和QA工程(以Playwright为首)。真实场景:您的团队正在向“你构建它,你运行它”的模型转变。您的开发人员已经在本地测试中使用Playwright,并希望使用相同的脚本来监控生产。解决方案:您将Checkly集成到您的GitHub Actions中。每当合并PR时,Checkly会自动使用开发人员为测试编写的完全相同的代码更新您的生产“心跳”监控。
8. Prometheus
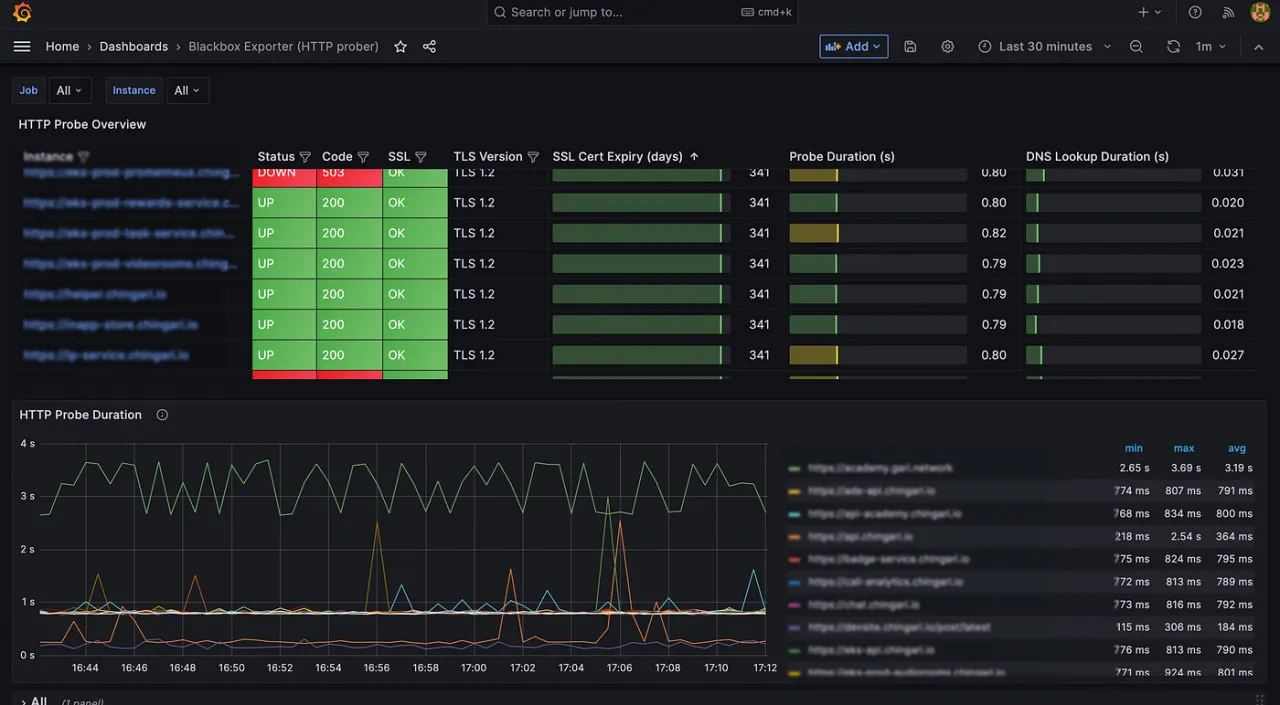 Prometheus是CNCF毕业的“黄金标准”云原生监控工具。它开创了基于拉取的指标模型和多维标签的使用,这对于跟踪短暂的Kubernetes pods至关重要。
Prometheus是CNCF毕业的“黄金标准”云原生监控工具。它开创了基于拉取的指标模型和多维标签的使用,这对于跟踪短暂的Kubernetes pods至关重要。
关键优势
- 无缝自动发现Kubernetes服务和容器。
- 为数学密集型操作(例如计算99百分位延迟)设计的强大查询语言。
- 每个服务器都是自包含的,没有外部数据库依赖,使其在停机期间具有弹性。
最佳适用:Kubernetes和微服务自动扩展。真实场景:您在EKS(亚马逊Kubernetes服务)上运行零售API。在“闪购”期间,您的HPA(水平Pod自动扩展器)启动200个新pods。解决方案:Prometheus通过Kubernetes API自动发现这些pods,立即抓取它们的指标,并在整个集群的p99延迟超过200ms时提醒您——而您无需手动将单个IP地址添加到配置文件中。
9. Zabbix
 Zabbix是基础设施监控的“瑞士军刀”。它是一个集中式、企业级的平台,擅长监控“混合环境”——您有现代Linux服务器、遗留Windows设备和物理网络设备的混合。
Zabbix是基础设施监控的“瑞士军刀”。它是一个集中式、企业级的平台,擅长监控“混合环境”——您有现代Linux服务器、遗留Windows设备和物理网络设备的混合。
关键优势
- Zabbix在单一本地Web界面中包含仪表板、警报和报告。
- 对物理硬件(路由器、交换机甚至服务器室温度计)的一级支持。
- 如果您能为它编写脚本(Python、Bash、Go),Zabbix就能监控它。
最佳适用:混合基础设施和多样化网络环境。真实场景:您管理着一个大学网络。您需要监控500个虚拟机、200个思科交换机和三个不同数据中心的温度。解决方案:您使用Zabbix和主动代理监控虚拟机,并使用SNMP监控交换机。您在Zabbix UI中构建一个“网络地图”,如果核心交换机宕机,它会变红,让您准确看到哪些服务器因硬件故障而被隔离。
10. Nagios(Core & XI)
 监控的“祖父”。Nagios基于简单的“插件”架构构建——它执行一个脚本,查看退出代码(0、1、2),并相应地发出警报。它以其稳定性而闻名,但因其1990年代的界面和配置摩擦而受到批评。
监控的“祖父”。Nagios基于简单的“插件”架构构建——它执行一个脚本,查看退出代码(0、1、2),并相应地发出警报。它以其稳定性而闻名,但因其1990年代的界面和配置摩擦而受到批评。
关键优势
- 如果它存在于数据中心,过去25年里就有人为其编写了Nagios插件。
- 核心引擎极其轻量,可以在最小硬件上运行。
- 它遵循简单的“检查->结果->警报”流程,易于故障排除。
最佳适用:稳定、遗留或“静态”环境。真实场景:您管理一系列在安全设施中“隔离”的关键任务服务器。这些服务器从不更改,不会自动扩展,必须保持24/7/365的正常运行。解决方案:您使用Nagios Core。它非常稳定,在更新期间不会崩溃。您使用一个简单的check_disk和check_ssh插件。它会在硬件RAID故障的瞬间发送一封可靠的电子邮件,并且没有任何“SaaS”或云依赖。
11. SolarWinds NPM

 SolarWinds网络性能监控(NPM)专注于网络设备和路径级监控。它跟踪可达性、跳数延迟、设备健康、接口流量、SNMP指标和网络拓扑。
SolarWinds网络性能监控(NPM)专注于网络设备和路径级监控。它跟踪可达性、跳数延迟、设备健康、接口流量、SNMP指标和网络拓扑。
关键优势
- 卓越的网络路径、跳数和接口可见性;
- SNMP和NetFlow支持,设备级指标;
- 对网络瓶颈和拓扑问题的洞察;
- 强大的网络相关故障诊断。
最佳适用:网络管理员和物理基础设施。真实场景:用户抱怨“互联网很慢”。您怀疑服务器室中的硬件问题或办公室之间的光纤跳数出现故障。解决方案:您使用NetPath。它为您显示网络路径的逐跳地图。您在达拉斯分公司的特定思科路由器上看到200ms的延迟峰值,确认这是硬件瓶颈,而不是软件错误。
12. LogicMonitor / ManageEngine OpManager
 LogicMonitor和ManageEngine是用于监控企业级基础设施的工具,具有合成模块和用户体验集成功能。它们适用于设备、服务器、虚拟机和应用监控。
LogicMonitor和ManageEngine是用于监控企业级基础设施的工具,具有合成模块和用户体验集成功能。它们适用于设备、服务器、虚拟机和应用监控。
关键优势
- 广泛的服务器、网络和应用基础设施;
- 预构建的集成和自动化便利;
- 完美的企业运营仪表板;
- 一些合成模块集成的选项。
最佳适用:混合IT和托管服务提供商(MSP)。真实场景:您为一家拥有10个全球办公室的公司管理IT,每个办公室都有自己的本地服务器、NetApp存储和VMware集群,全部连接到Azure。解决方案:您使用LogicMonitor的收集器架构。它自动发现您网络上的2000多个设备,并构建一个“企业仪表板”,在一个视图中显示您的物理存储、虚拟机和云实例的健康状况。
如何选择您的监控堆栈?
选择监控套件不再是“寻找最佳工具”,而是最小化事件与其解决之间的差距。对于现代DevOps或SRE团队,决策过程应优先考虑以下几点:
1. 评估覆盖范围与工具扩散
问问您的团队是否能够现实地管理一个“最佳品种”堆栈(例如,Prometheus用于指标,Checkly用于脚本,SolarWinds用于网络)。虽然专业化,但这往往会导致“数据孤岛”。像Dotcom-Monitor或Datadog这样的统一平台通过直接将合成故障与基础设施健康相关联,减少了在高压停机期间的上下文切换。
2. 优先考虑自动化和IaC支持
在云原生环境中,手动配置是一种负担。确保您选择的工具支持Terraform、Pulumi或全面的CLI。如果您无法将合成检查作为服务部署的一部分进行配置,该工具最终将成为您工程速度的瓶颈。
3. 评估信号与噪声比
对SRE来说,最大的威胁是警报疲劳。寻找提供复杂警报逻辑的工具,例如“X个故障来自Y个位置”,以过滤掉瞬时网络波动。避免强迫“一个尺寸适合所有”的阈值的平台,这往往会导致“狼来了”和被忽视的通知。
4. 分析总拥有成本(TCO)
除了标价外,还要考虑运营开销。像Zabbix或Prometheus这样的开源解决方案在许可上是“免费”的,但在维护、打补丁和扩展所需的工程时间上却很昂贵。SaaS平台以更高的许可成本换取减少的“劳作”,使您的团队能够专注于站点可靠性,而不是监控服务器维护。
许多团队采用分层堆栈或全力投入统一平台,如Dotcom‑Monitor。什么对您最好取决于您的预算、系统、团队规模和团队专业知识。
底线
在2026年,“最佳”工具是消除DevOps、SRE和QA团队之间孤岛的工具。如果您正在管理复杂的云原生环境,Datadog或Dynatrace提供无与伦比的关联,尽管价格较高。对于寻求强大统一方法的团队,该方法结合了深度协议检查与全球合成交易,而没有“企业税”,Dotcom-Monitor提供了“外部”和“内部”可见性的最务实平衡。最终,您的目标应该是将监控视为代码。优先考虑具有强大API支持和Terraform提供程序的工具,以便您的监控能够随着基础设施的快速发展而演变。
Frequently Asked Questions
- 通过中央系统使用警报
- 明智地使用严重性级别和阈值
- 在维护窗口期间抑制
- 将相关警报分组并过滤重复项
- 根据历史虚假警报进行调整