 Les applications web modernes ont déplacé leur centre de gravité. La page n’est plus le système — c’est le runtime. Des frameworks comme React, Angular, Vue, Next.js, SvelteKit, Remix et Nuxt traitent le HTML comme un chargeur de démarrage, et la véritable application n’émerge qu’après l’hydratation, le routage, la récupération des données et les rerenderings continus. Ce que les utilisateurs voient dépend entièrement de l’exécution JavaScript, et non du balisage statique.
Les applications web modernes ont déplacé leur centre de gravité. La page n’est plus le système — c’est le runtime. Des frameworks comme React, Angular, Vue, Next.js, SvelteKit, Remix et Nuxt traitent le HTML comme un chargeur de démarrage, et la véritable application n’émerge qu’après l’hydratation, le routage, la récupération des données et les rerenderings continus. Ce que les utilisateurs voient dépend entièrement de l’exécution JavaScript, et non du balisage statique.
Les équipes découvrent généralement ce changement lorsque l’interface semble se charger mais que rien ne fonctionne. Les boutons ne répondent pas, les panneaux restent vides et les flux se cassent sans erreur serveur évidente. Le routeur — pas la page — détermine si l’application est réellement utilisable, pourtant la plupart des outils de surveillance ne l’observent jamais.
Si vous vous fiez à une surveillance centrée sur la page pour des architectures SPA, CSR, SSR ou hybrides, vous regardez la coquille au lieu de l’application. Cet article explique comment surveiller correctement les systèmes dirigés par le routage, et pourquoi les flux synthétiques et le RUM doivent suivre le runtime plutôt que le HTML initial.
Surveiller après le chargement de la page
Dans une application multi-page, le cycle de vie de la page était le cycle de vie de l’application. Vous mesuriez le temps de chargement, la disponibilité du DOM, les erreurs et les réponses serveur. Les dépendances étaient stables et visibles.
Le routage côté client casse cette hypothèse. Le premier chargement n’est qu’un parmi d’autres. Les vraies erreurs se produisent désormais dans des états que les navigateurs ne réinitialisent pas : arbres de composants dynamiques, données accumulées dans le store, caches de fetch, guards de route, feature flags et transitions entre une « page » logique et une autre sans rechargement d’URL. Si votre surveillance s’arrête à DOMContentLoaded, vous manquez 90 % du runtime.
La question opérationnelle devient : comment mesurer une application qui ne « recommence » plus quand l’utilisateur change d’écran ?
La réponse est : vous suivez le routeur.
Pourquoi le routage côté client casse les modèles traditionnels de surveillance
Les frameworks de routage interceptent les événements de navigation, rendent de nouvelles vues en place et effectuent des appels asynchrones vers des services distants. L’URL peut changer, ou pas. Le DOM peut se mettre à jour partiellement, ou se rerender complètement. Il n’y a pas de concept de « page complète ». Il y a seulement « vue montée », « données résolues » et « store mis à jour ».
Les contrôles traditionnels de disponibilité supposent :
- Un chargement de page frais.
- Une réponse HTML déterministe.
- Un DOM complet avant interaction.
Aucune de ces suppositions ne survit dans les architectures SPA/CSR. Une transition de route peut échouer alors que l’URL paraît valide. Un composant peut se monter alors que sa couche de données est cassée. Un service de feature flag peut retourner des payloads différents selon les personas, entraînant des rendus extrêmement incohérents que les moniteurs synthétiques doivent détecter — et non ignorer comme « transitoires ».
La surveillance devient comportementale plutôt que basée sur le document. Vous ne pouvez plus simplement vérifier une URL ; vous devez valider une expérience.
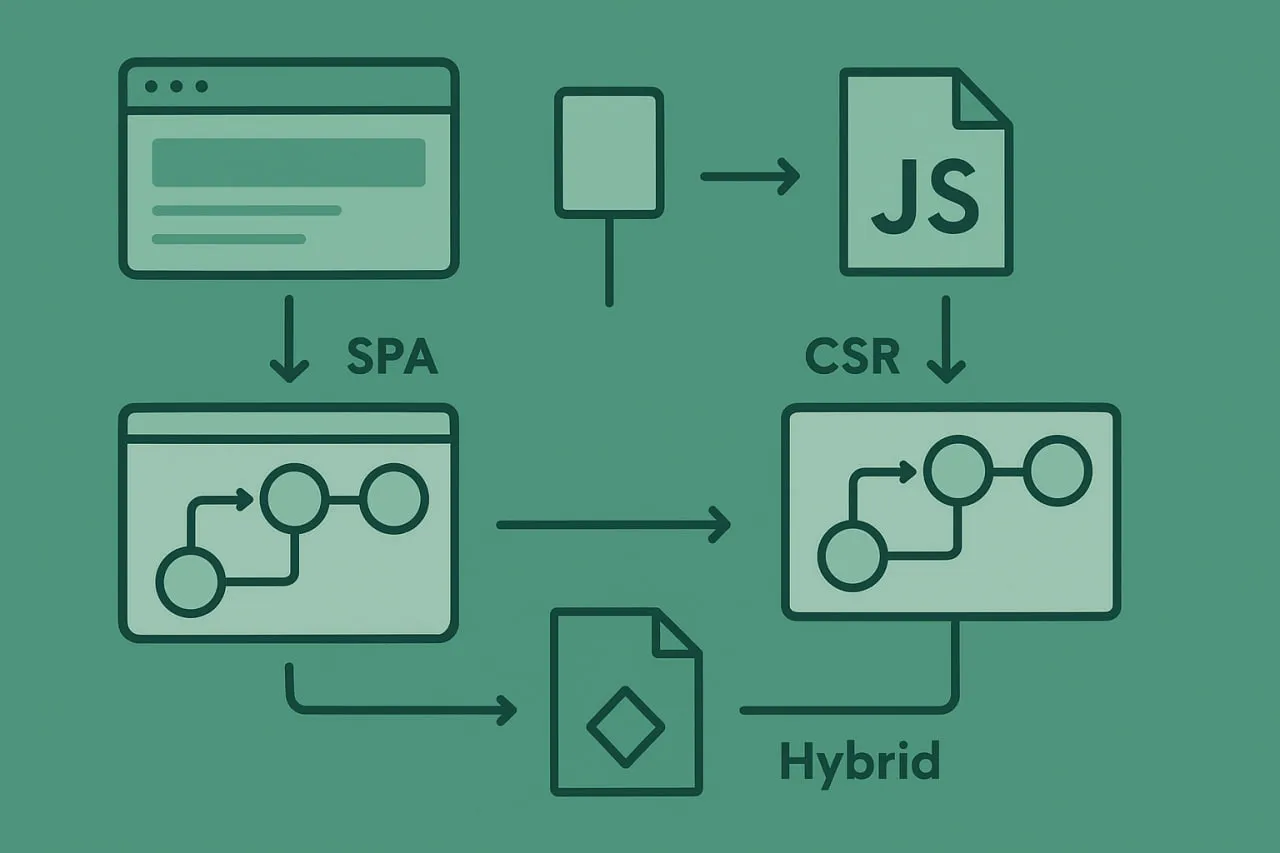
Le spectre architectural : SPA, CSR, SSR, SSG et hybride
Le développement web s’est fragmenté en un spectre de modèles de rendu :
- SPA/CSR pur charge une seule page HTML et délègue tout au JavaScript. La navigation est entièrement pilotée côté client. La surveillance de type UserView doit comprendre l’exécution, pas les pages.
- Frameworks SSR (Next.js, Nuxt, SvelteKit) réintroduisent un premier chargement rendu côté serveur mais utilisent le routage côté client pour les navigations suivantes. Résultat : le premier paint se comporte comme une MPA, mais chaque interaction après se comporte comme une SPA.
- SSG et ISR produisent du HTML statique à l’avance, mais l’hydratation dicte toujours si l’application fonctionne. Des pages statiques peuvent sembler correctes tandis que leurs composants hydratés échouent en silence.
- Modèles hybrides mixent les modes par route ou par environnement. Un utilisateur non connecté peut recevoir du SSR, alors qu’un utilisateur connecté peut recevoir du CSR.
L’architecture n’influence que la première render. La surveillance doit se concentrer sur le runtime qui suit.
Modes réels de défaillance dans les applications SPA/CSR
Les applications dirigées par le routage introduisent une toute nouvelle catégorie de défaillances que les moniteurs traditionnels ne voient jamais.
Les échecs d’hydratation sont courants : la coquille HTML se rend, mais le JavaScript rencontre un décalage entre le balisage rendu côté serveur et celui rendu côté client. L’application semble vivante mais est figée.
Les échecs d’initialisation du routeur apparaissent lorsque les définitions de route entrent en conflit, des modules lazy échouent à se charger ou le routeur ne parvient pas à résoudre l’état courant. L’utilisateur voit un chrome fonctionnel mais sans contenu.
La corruption du store d’état survient lorsque Redux, Vuex, NgRx, Zustand ou d’autres stockages transportent un état malformé à travers les navigations. Comme les SPAs accumulent l’état au lieu de le réinitialiser, les défaillances apparaissent profondément dans des flux multi-étapes — précisément là où la plupart des moniteurs cessent de mesurer.
Les échecs silencieux d’API se produisent lorsque le routeur navigue avec succès, mais que la couche de données renvoie des réponses 500 ou 403. La vue se charge mais affiche des widgets incomplets ou vides. La surveillance doit considérer cela comme une défaillance, pas comme un succès dégradé.
Les bundles obsolètes sont une menace constante. Les CDN servent fréquemment du JS périmé, causant des incompatibilités de version qui font planter l’hydratation ou le routage. Ces défaillances varient selon les régions, et la surveillance synthétique est spécialement adaptée pour les détecter.
Chacun de ces modes de défaillance survient après le chargement de la page. La plupart n’apparaissent qu’après une séquence d’actions utilisateur. Si vos modèles de surveillance n’incluent pas de flux synthétiques multi-étapes, vous ne les verrez pas avant que les utilisateurs ne se plaignent.
Mesurer la navigation dans les frameworks fortement routés
Le succès d’une navigation dans une SPA ne peut pas être déterminé en attendant que le DOM se stabilise. Le runtime ne se stabilise jamais.
À la place, la surveillance doit mesurer :
- Le temps entre l’action utilisateur (clic/tap) et la vue routée.
- La complétion du montage du composant, pas la simple disponibilité du document.
- La résolution des données — les appels XHR/fetch nécessaires se sont-ils terminés, et l’UI les a-t-elle consommés ?
- La confirmation UI — la page a-t-elle réellement rendu l’état interactif attendu ?
Les métriques de « temps de chargement » deviennent insignifiantes. Ce qui compte, c’est la latence de transition, la complétude de l’hydratation et l’intégrité des dépendances de données.
Un moniteur doit observer la timeline du parcours utilisateur plutôt que le cycle de vie du document.
Surveillance synthétique pour les flux de routage multi-étapes
Surveiller des applications dirigées par le routage exige une exécution complète du navigateur, pas des vérifications HTTP légères. Les transitions de route ne se comportent pas comme des chargements de page, et même de nombreux tests scriptés échouent car ils supposent des changements d’URL prévisibles ou des états DOM statiques. Un flux synthétique doit se comporter comme un utilisateur réel : il doit cliquer, naviguer et interagir de manière à déclencher le routeur. Il doit aussi reconnaître les événements du routeur même quand l’URL reste la même, suivre le DOM pendant qu’il mute en réponse aux mises à jour de composants, et suivre le travail asynchrone que chaque transition déclenche.
Le plus important : un test doit confirmer que l’UI atteint réellement l’état attendu. Cela signifie surveiller la résolution de la couche de données, attendre les composants montés qui en dépendent, et vérifier l’interface rendue plutôt que de chronométrer un chargement de document. C’est la seule manière fiable de savoir si une vue routée est complète et fonctionnelle.
Les défaillances se cachent souvent entre les étapes. Une SPA peut naviguer avec succès plusieurs fois avant que l’état accumulé, la pression mémoire ou un cas limite d’un guard de route ne finisse par casser le flux. Ce sont ces problèmes que rencontrent les utilisateurs — et que les moniteurs simples ne voient jamais. C’est pourquoi la surveillance synthétique pour les frontends modernes doit modéliser des séquences réalistes plutôt que des interactions isolées, et pourquoi les tests sensibles au routage sont devenus une infrastructure essentielle, pas un luxe.
Surveiller la couche API derrière le routeur
Les SPAs traitent le backend comme une constellation de microservices. La navigation déclenche des appels API vers :
- Endpoints GraphQL
- Services REST
- Moteurs de recherche et de recommandation
- Services de feature flag
- Endpoints de personnalisation
- Couches d’authentification et d’autorisation
Le routeur peut réussir alors que les APIs sous-jacentes échouent. Du point de vue de l’utilisateur, l’application est cassée même si la coquille se charge.
La surveillance doit corréler le succès de la route avec le succès des services. Si l’UI charge un composant mais échoue à le remplir parce qu’une API a répondu lentement ou incorrectement, le flux synthétique doit traiter cela comme une défaillance. Sinon, la surveillance affichera un tableau de bord vert pendant que les utilisateurs restent bloqués sur des écrans à moitié rendus.
La dimension cache, CDN et bundle
Les applications dirigées par le routage dépendent beaucoup plus des CDN et des pipelines d’assets que les sites traditionnels rendus côté serveur, et la stabilité de toute l’expérience dépend de l’intégrité des bundles. Quand les règles de cache sont mal configurées, quand les ETags ou les hashes de version dévient, ou quand une région du CDN sert un chunk obsolète, le routeur peut casser même lorsque le serveur continue de renvoyer 200-OK. Ces échecs se manifestent par des incompatibilités d’hydratation entre le HTML et le JavaScript, par des pages qui chargent la coquille correcte mais exécutent le mauvais bundle, et par des modules lazy qui échouent parce que leur chunk correspondant ne correspond plus à la build actuelle.
Ces problèmes apparaissent rarement de manière uniforme à l’échelle mondiale. Une région peut recevoir des assets à jour tandis qu’une autre accuse un retard de minutes ou d’heures, créant des comportements incohérents que seuls certains utilisateurs expérimentent. Et parce que les SPAs dépendent d’un runtime « chaud », beaucoup de ces échecs ne se révèlent qu’après une séquence de navigations, pas lors d’un premier chargement propre.
La surveillance doit être capable de faire remonter ces incohérences. Un test mono-région ou une vérification synthétique qui commence toujours par un chargement froid de la page manquera la majorité des échecs liés au CDN. Seuls des flux synthétiques stateful multi-régions fournissent une barrière fiable, car ils exposent le comportement des bundles et du cache que les utilisateurs voient réellement — et non la version simplifiée que les outils de surveillance supposent souvent.
Surveiller correctement les frameworks SSR et hybrides
Le SSR introduit un angle mort courant : le HTML rendu côté serveur semble correct, donc les équipes supposent que la surveillance est complète. Mais le SSR n’est qu’une moitié du framework. L’hydratation doit réussir avant que les interactions utilisateur soient disponibles. Si l’hydratation échoue, la page est une carte postale inerte.
La surveillance doit séparer :
- La performance et la disponibilité du SSR
- La complétude de l’hydratation
- La performance de navigation CSR
- La stabilité des navigations « chaudes »
Les frameworks hybrides compliquent encore davantage. Une même route peut se comporter différemment selon l’état d’authentification, la géolocalisation, les assignations d’A/B testing ou les variations de feature flag.
Cela signifie que la surveillance synthétique doit évaluer plusieurs personas. Un seul flux de connexion n’est pas suffisant. Un seul chemin de route n’est pas suffisant. Les modèles hybrides font varier le comportement sous vos pieds, et le moniteur doit parcourir tous les chemins que les utilisateurs peuvent emprunter.
Stratégies synthétiques de surveillance qui fonctionnent réellement pour les SPAs
Une surveillance efficace adopte un modèle comportemental, centré sur le runtime.
Vous simulez des interactions utilisateur qui actionnent le routeur plutôt que de mesurer ce que le serveur a envoyé. Vous attendez des résultats visibles plutôt que la disponibilité du DOM. Vous observez automatiquement les appels API au lieu de le faire manuellement. Vous considérez l’absence de contenu d’un widget comme une défaillance plutôt qu’un succès partiel acceptable.
Les moniteurs qui capturent les logs de la console révèlent les erreurs d’hydratation, les plantages du routeur et les imports dynamiques ratés. Les outils qui suivent les XHR/fetch dévoilent des échecs de données cachés derrière des navigations réussies. Des assertions sur l’UI rendue garantissent que l’application se comporte comme l’utilisateur l’attend, et pas seulement comme le serveur a répondu.
La surveillance devient une lentille sur la correction du runtime, et non sur la correction de la page.
RUM + Synthétique : un modèle de visibilité combiné pour les frameworks de routage
Le RUM (Real User Monitoring) fournit des données organiques du monde réel. Il met en évidence les dégradations régionales, les disparités selon les appareils, les latences en queue de distribution et les schémas de comportement utilisateur.
La surveillance synthétique offre des workflows déterministes, la détection cohérente des régressions et des conditions contrôlées.
Les applications dirigées par le routage exigent les deux.
Le RUM seul ne peut pas détecter les régressions futures. Le synthétique seul ne capture pas la variabilité du monde réel. Ensemble, ils forment la surface complète de surveillance pour les SPAs et les hybrides :
- Le synthétique détecte les ruptures tôt.
- Le RUM confirme l’impact.
- Le synthétique reproduit le problème.
- Le RUM valide la correction.
Ce cycle vertueux est essentiel pour des frontends complexes qui modifient dynamiquement leur comportement.
Dérive de version, vitesse de release et rôle du monitoring synthétique
Les pipelines modernes de frontend produisent constamment de nouvelles versions, et les systèmes de déploiement distribuent souvent ces versions de manière inégale. Un edge CDN peut mettre des minutes à purger un asset obsolète, tandis qu’une page ISR peut se régénérer à des intervalles différents, et un rollout peut exposer un nouveau bundle à seulement un pourcentage d’utilisateurs. Dans cet environnement, deux personnes chargeant « la même page » peuvent en réalité exécuter des builds incompatibles de l’application.
La surveillance synthétique devient la force stabilisatrice dans ce paysage. Elle révèle quand le HTML et le JavaScript ne correspondent plus, quand un edge sert des bundles obsolètes, quand des feature flags s’activent en combinaisons inattendues, ou quand des modules lazy pointent vers des chunks manquants ou invalides. Ce ne sont pas des cas marginaux — ce sont des artefacts routiniers du développement frontend à haute vélocité. La dérive de version est l’une des causes les plus courantes d’échecs d’hydratation, d’erreurs de routage et de rendus incohérents. Seuls des tests synthétiques qui exercent l’application réelle, dans de vrais environnements de navigateur, exposent constamment ces problèmes avant que les utilisateurs ne les rencontrent.
Un blueprint de monitoring pour les applications CSR/SPA/SSR
Une stratégie robuste de monitoring pour les applications dirigées par le routage ne peut pas s’appuyer sur un seul type de vérification. Elle nécessite des couches. À la fréquence la plus élevée, vous validez si le runtime démarre et si le routeur s’initialise correctement. À cadence modérée, vous exercez des chemins de navigation clés et confirmez que les vues principales se rendent avec les données attendues attachées. Des workflows plus profonds tournent moins souvent, mais simulent des parcours utilisateurs complets, révélant comment l’état se comporte sur des séquences de transitions plutôt que sur des écrans isolés.
La surveillance d’API doit être alignée avec cela, car le routage ne réussit que lorsque les services sous-jacents fournissent des réponses cohérentes. Des vérifications d’intégrité des assets complètent le dispositif en garantissant que bundles, chunks et artefacts servis par le CDN appartiennent à la même lignée de build. Et des tests basés sur des personas complètent le blueprint en capturant les variations de routage introduites par l’authentification, les rôles, les localisations et les feature flags. La combinaison produit une visibilité opérationnelle sur l’ensemble du runtime plutôt qu’une vision étroite du seul premier chargement.
Comment Dotcom-Monitor prend en charge la surveillance consciente du routage
Les applications dirigées par le routage exigent une surveillance qui capture le comportement plutôt que des instantanés du balisage. C’est la lentille que nous utilisons chez Dotcom-Monitor. Nos tests basés navigateur évaluent les applications de la même manière que les utilisateurs, en suivant les transitions de route, en observant les flux de données asynchrones et en validant que les composants deviennent interactifs après l’hydratation. Parce que nous exécutons depuis plusieurs géographies et profils d’appareils, nous découvrons la dérive de CDN, les problèmes sensibles au réseau et les défaillances subtiles qui n’apparaissent qu’après plusieurs navigations.
Notre scripting de workflows reproduit des parcours réels utilisateur sur des chemins authentifiés et non authentifiés, ce qui nous permet d’exposer des problèmes de routage et d’état que des vérifications basées sur la page ne détectent jamais. Nous nous concentrons sur le runtime lui-même — le routeur, la couche de données et le graphe de bundles en évolution — parce que c’est cela qui définit la fiabilité des frontends modernes. Pour les architectures SPA, CSR, SSR et hybrides, cette profondeur de visibilité est désormais une exigence, et non un avantage.
Conclusion : surveiller le runtime, pas la page
Le routage côté client a changé de façon permanente le comportement du web. L’application ne redémarre plus à chaque navigation. Les défaillances ne se présentent pas comme des pages cassées — elles se présentent comme des comportements cassés. La surveillance doit évoluer pour accompagner ce changement.
Les outils qui mesurent les chargements de page, les arbres DOM statiques ou les réponses serveur ne représentent pas le comportement des SPAs, SSR et architectures hybrides modernes. La surveillance doit suivre le routeur, la couche d’état, le graphe de bundles et les dépendances de données qui définissent la véritable expérience utilisateur.
L’avenir du monitoring est conscient du runtime. Il est comportemental, orienté par les routes, sensible aux versions et profondément intégré à l’exécution des frameworks. Les organisations qui continueront à ne surveiller que le premier paint auront des dashboards « verts » pendant que les utilisateurs verront des panneaux vides.
Les frameworks de routage ont déplacé la complexité du serveur vers le navigateur. La surveillance doit se déplacer avec eux.