Die Auswahl der richtigen Infrastruktur- und synthetischen Überwachungstools geht nicht mehr nur darum, ein Uptime-Kästchen abzuhaken; es geht darum, die Sichtbarkeitslücke zwischen der Gesundheit Ihres Backends und der tatsächlichen Endbenutzererfahrung zu schließen. In einer modernen DevOps-Umgebung kann ein Ausfall Ihrer DNS-Routing oder eine latente 3rd-Party-API ebenso katastrophal sein wie ein Serverabsturz, doch diese “Outside-In”-Probleme bleiben oft unentdeckt von traditionellen internen Monitoren.
Dieser Leitfaden bewertet die 12 besten Infrastruktur- und synthetischen Überwachungstools, die speziell für technische Teams zusammengestellt wurden, die MTTR (Mean Time to Resolution) reduzieren und “blinde Flecken” in ihrem Produktions-Stack beseitigen müssen.
Synthetische vs. Infrastrukturüberwachung
Während synthetische Überwachung funktionale Workflows von globalen Standorten validiert, bietet die Infrastrukturüberwachung die detaillierte Telemetrie, die benötigt wird, um die Hardware- und Netzwerkfehler zu diagnostizieren, die dazu führen, dass diese Workflows fehlschlagen.
| Überwachungsart | Was es tut | Wichtige Anwendungsfälle & Vorteile |
| Synthetische Überwachung | Simuliert Benutzeraktionen, skriptbasierte Workflows und geplante API-Aufrufe | Erfasst fehlerhafte Abläufe & Verzögerungen. Benchmarking über Standorte. Uptime/Transaktionsgesundheit |
| Infrastrukturüberwachung | Verfolgt: Server, Netzwerkgeräte, Dienste (DNS, TCP/UDP, Ping usw.) & Ressourcenmetriken | Erkennt: Backend- & Protokollebene-Fehler, Dienstunterbrechungen und Ressourcensättigung |
Vergleich der 12 besten Infrastruktur- und synthetischen Überwachungstools
| Tool | Synthetisch | Infrastruktur | Highlights | Trade-offs |
| Dynatrace | ✅ | ✅ | KI-gesteuerte Sichtbarkeit, Verknüpfung von Benutzerflüssen und Backend-Metriken | Komplex. Kosten können schnell steigen |
| Dotcom-Monitor | ✅ | ✅ | Synthetische und Dienstüberwachung auf einer Plattform | Vermeidet Toolfragmentierung. Bietet modulare Skalierung |
| New Relic | ✅ | ✅ | Skripte für synthetische Workflows. Starke Sichtbarkeit | Teuer. Hat eine Lernkurve |
| Datadog | ✅ | ✅ | Vollständige Ansicht von UI, Infrastruktur, Protokollen bis hin zu Metriken | Teuer in großem Maßstab |
| Site24x7 | ✅ | ✅ | All-in-One: Web, Server, Netzwerk, Cloud, synthetische & Infrastrukturabdeckung | Tiefe kann in einigen Modulen geringer sein |
| Pingdom | ✅ | – | Zuverlässig in Uptime, Transaktions- & Seitenladeüberwachung | Fehlen tiefgehender Infrastruktur- & Protokollebene-Checks |
| Checkly | ✅ | – | JS/Playwright-Skripting für synthetische Workflows | Erfordert Skripting-Expertise. Keine integrierten Infrastruktur-Checks |
| Zabbix | – | ✅ | Hochgradig vielseitige Plattform für hybride Umgebungen (SNMP, IPMI, JMX & Agenten). | UI-lastige Verwaltung; Skalierung erfordert signifikante Datenbankanpassungen. |
| Nagios | – | ✅ | Legendäre Stabilität für statische/legacy Umgebungen mit einer riesigen Plugin-Bibliothek. | Hoher Konfigurationsaufwand; veraltete UI und fehlt native Zeitreihen-Diagramme. |
| Prometheus | – | ✅ | Der CNCF-Standard für K8s-native Metriken und multidimensionale Kennzeichnung. | Benötigt externen Speicher (Thanos/Cortex) und zusätzliche Tools für Protokolle/synthetische. |
| SolarWinds Network Performance Monitor (NPM) | – | ✅ | Exzellente Netzwerkpfad-, Hop-, Geräteebene-, SNMP-, Flussanalyse | Weniger Fokus auf synthetische Überwachung |
| LogicMonitor, ManageEngine OpManager | – oder Hybrid | ✅ | Infrastruktur-, Netzwerk-, Systemüberwachung mit einigen synthetischen oder Integrationsfunktionen | Schwache synthetische Überwachung, Add-ons sind erforderlich. |
1. Dynatrace

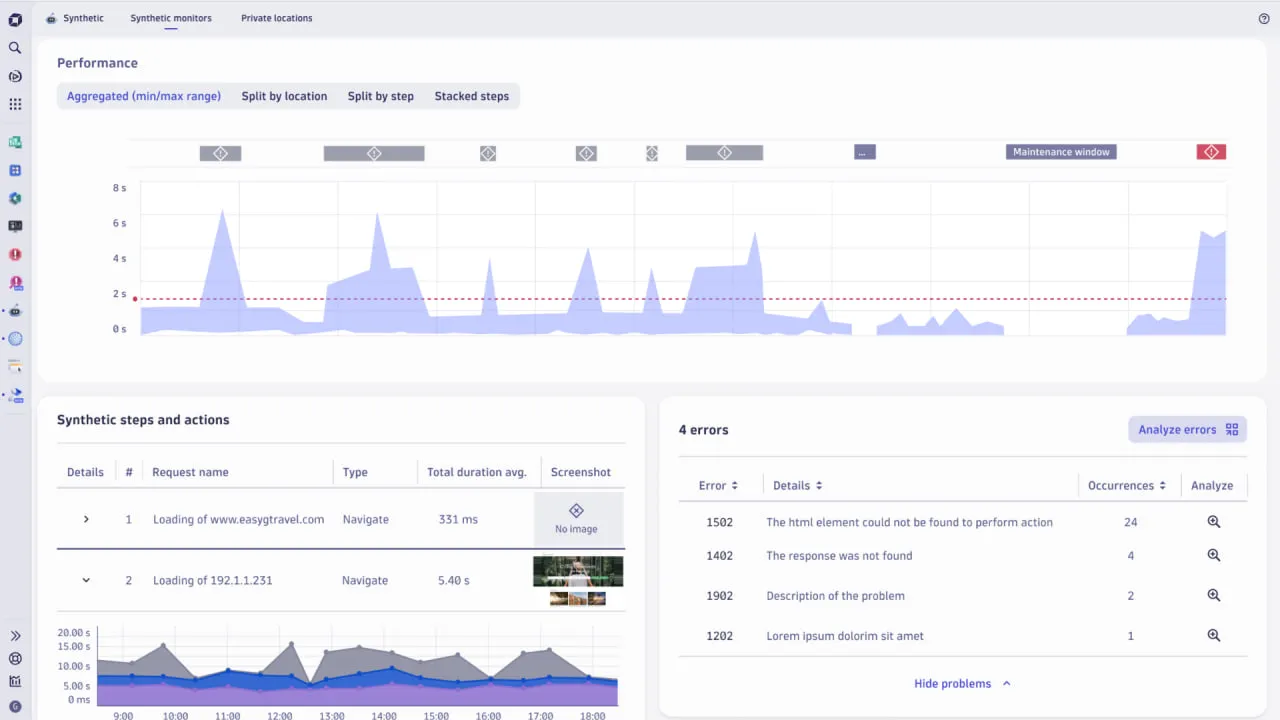
Dynatrace ist eine Lösung, die Funktionen wie synthetische Überwachung, echte Benutzerüberwachung, Infrastruktur- und Anwendungsmetriken sowie automatische Ursachenanalyse kombiniert. Die OneAgent-Architektur sammelt Analysen durch kontextuelle Analytik, KI und Automatisierung.
Wichtige Vorteile
- KI-gesteuerte Anomalieerkennung und -analyse;
- Korrelation von synthetischen Checks mit Infrastruktur-Trace;
- Vollständige Abdeckung, einschließlich globaler synthetischer Überwachung;
- Gut für hybride, Cloud- und komplexe Unternehmensumgebungen.
Am besten geeignet für: Massive Unternehmenskomplexität & automatisierte Ursachenanalyse.
Real-Life-Szenario: Ihre Bank migriert ein legacy Monolith zu einer hybriden Cloud-Mikroservices-Architektur. Eine einzelne “Geld überweisen”-Anfrage berührt jetzt 50+ Dienste über AWS und ein lokales Rechenzentrum.
Die Lösung: Sie setzen den OneAgent ein. Wenn die Transaktionslatenz ansteigt, kartiert die KI von Dynatrace (Davis) automatisch die Topologie und sagt Ihnen: “Die Verzögerung liegt nicht im Code; es ist ein spezifischer Datenbank-Lock im lokalen SQL-Cluster, der eine Kaskade verursacht.”
2. Dotcom‑Monitor

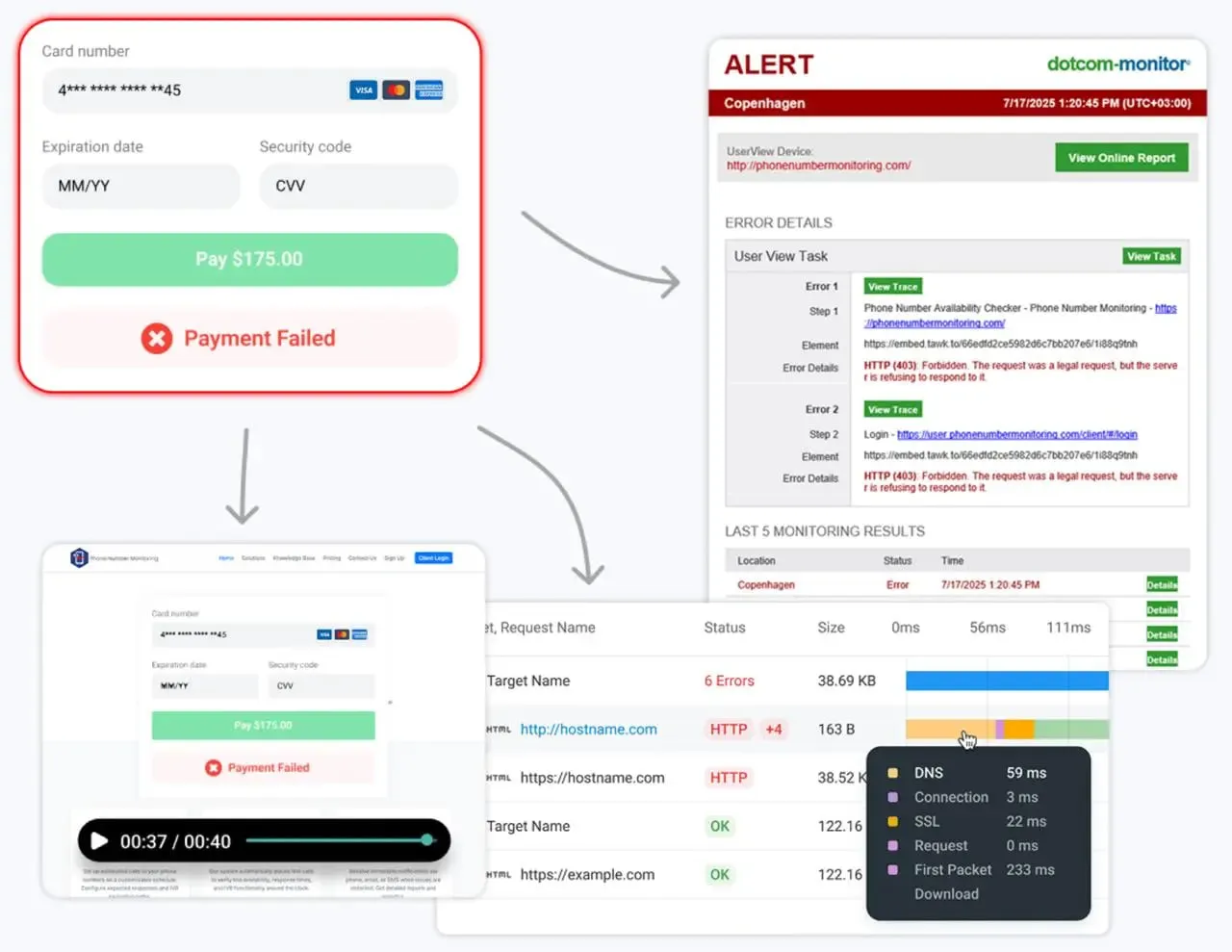
Dotcom-Monitor ist eine einheitliche Plattform, die sowohl synthetische Überwachung (Web-Performance, skriptbasierte Abläufe, API-Checks) als auch Infrastrukturüberwachung (DNS, FTP, ICMP, UDP, TCP-Port-Checks, VoIP) anbietet. Es integriert auch Server- und Geräteüberwachung über sein ServerView-Modul für vollständige Sichtbarkeit mit nur einer Schnittstelle.
Wichtige Vorteile
- Findet zugrunde liegende Anomalien durch Stimuli von Benutzerinteraktionen;
- Multi-Standort-Checks zur Verbesserung der Benutzererfahrung und Infrastruktur;
- Alles unter einem einheitlichen Dashboard, ohne die Tools wechseln zu müssen;
- Modularer Ansatz – aktivieren Sie Infrastrukturmodule nach Bedarf;
- Reduziert den operativen Aufwand, wie das Verwalten mehrerer Tools.
Am besten geeignet für: Globale Benutzererfahrung & Multi-Protokoll-Zuverlässigkeit.
Real-Life-Szenario: Sie betreiben eine stark frequentierte E-Commerce-Plattform mit einer globalen Kundenbasis. Sie hatten mehrere Vorfälle, bei denen die Website “online” war, laut internen Metriken, aber Kunden in Europa konnten aufgrund regionaler DNS-Latenz oder eines Zeitüberschreitungs bei einem Drittanbieter-Zahlungsgateway keine Bestellungen abschließen.
Die Lösung: Sie verwenden Dotcom-Monitor, um echte Browser-synthetische Abläufe von über 30 globalen Standorten alle 5 Minuten auszuführen. Wenn ein regionaler ISP in London ein Routing-Problem hat, erhalten Sie eine Benachrichtigung mit einem Wasserfall-Diagramm, das den genauen 404- oder 500-Fehler zeigt, bevor Ihr Helpdesk mit Tickets überflutet wird.
3. New Relic

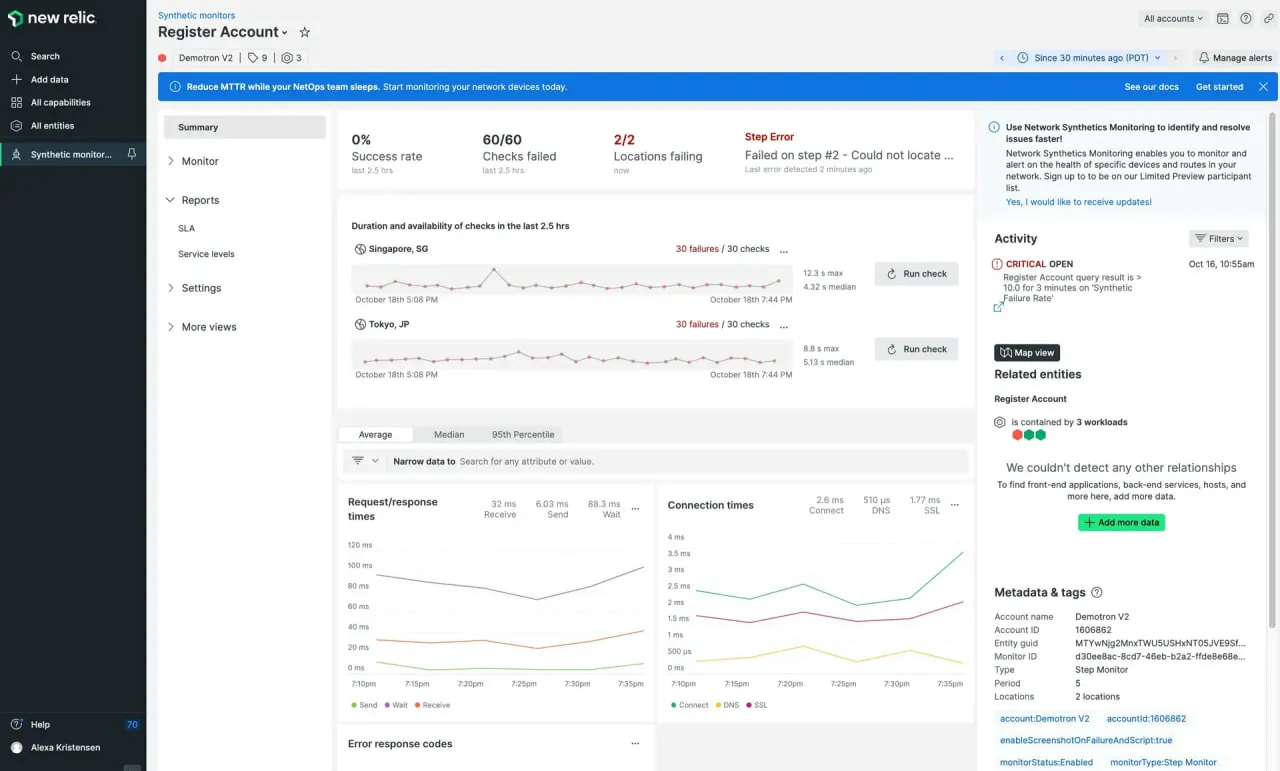
New Relic ermöglicht es Ihnen, Browser- und API-Workflow-Skripte zu schreiben und diese Ergebnisse in seinen Sichtbarkeits-Stack (APM, Infrastruktur, Protokolle) zu integrieren. Es ist für Teams konzipiert, die alles in einem Ökosystem haben möchten.
Wichtige Vorteile
- Reiche Skripting-Flexibilität für komplexe Benutzerflüsse;
- Starke Integration mit Backend-Metriken und Protokollen;
- Einheitliche Dashboards und Alarmsystem;
- Gute Unterstützung und Ökosystem.
Am besten geeignet für: Tiefe Anwendungs-Debugging & Code-Level-Optimierung.
Real-Life-Szenario: Nach einem großen Deployment am Freitagnachmittag verdoppelt sich die Antwortzeit Ihrer API. Die Protokolle zeigen, dass alles “OK” ist, aber die Benutzer beschweren sich.
Die Lösung: Sie verwenden New Relic APM, um in einen “Transaktions-Trace” einzutauchen. Es zeigt, dass ein neuer regulärer Ausdruck in Zeile 402 Ihres Python-Controllers CPU-Spitzen verursacht – sodass Sie die spezifische Codezeile innerhalb von Minuten zurücksetzen und beheben können.
4. Datadog

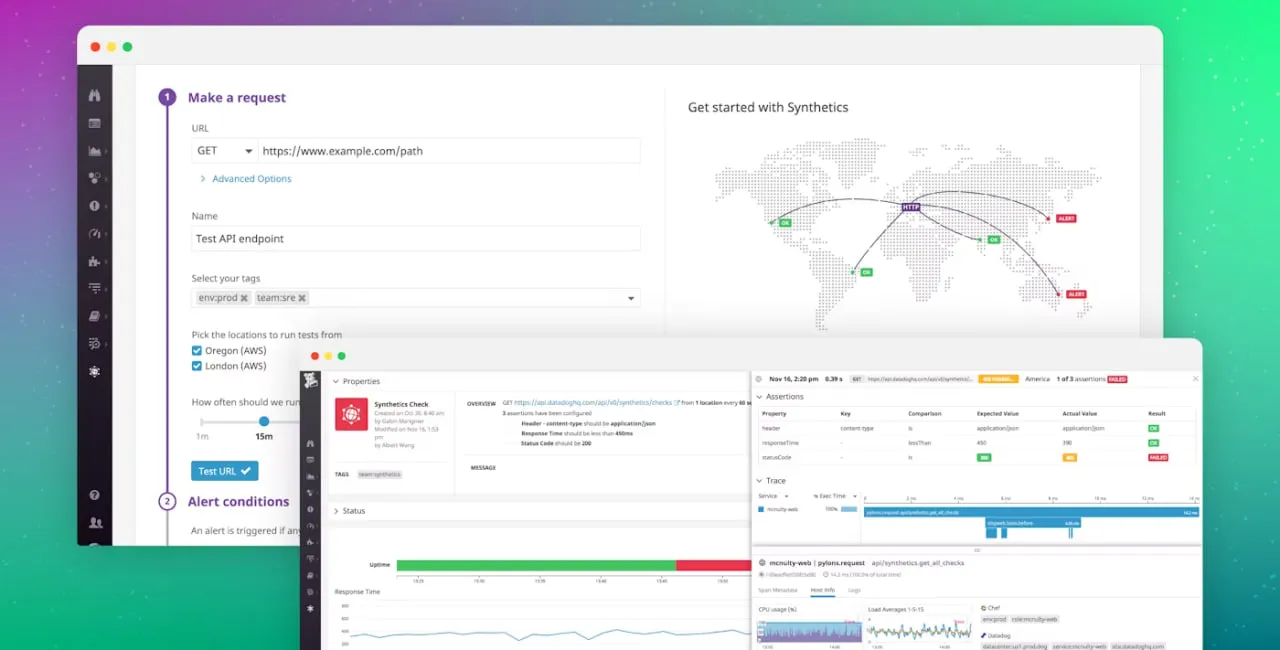
Datadog verfolgt einen integrativen Ansatz, der synthetische Überwachung mit Metriksammlung, Protokollen, Tracing und Infrastrukturgesundheit kombiniert. So bietet es Ihnen eine All-in-One-Lösung.
Wichtige Vorteile
- Einheitliche Korrelation zwischen synthetischen, Infrastruktur- und Protokollen;
- Benutzerdefiniertes Dashboard und Visualisierungen;
- Breite Integrationen über Cloud-Dienste, Container, Datenbanken usw.;
- Kann für große Systeme skaliert werden.
Am besten geeignet für: Hochgeschwindigkeits-Cloud-native Teams.
Real-Life-Szenario: Sie verwalten eine Flotte von über 500 Kubernetes-Mikroservices, die 20 Mal am Tag hoch- und heruntergefahren werden. Sie müssen wissen, ob ein spezifisches “Canary”-Deployment Fehler in einem nachgelagerten Dienst verursacht.
Die Lösung: Sie verwenden Service Maps und Log-Korrelation. Wenn ein Pod abstürzt, klicken Sie auf den Fehler in Ihrem Dashboard und sehen sofort die spezifischen Protokolle und Traces für diesen genauen Container, gefiltert nach dem “Versions”-Tag.
5. Site24x7

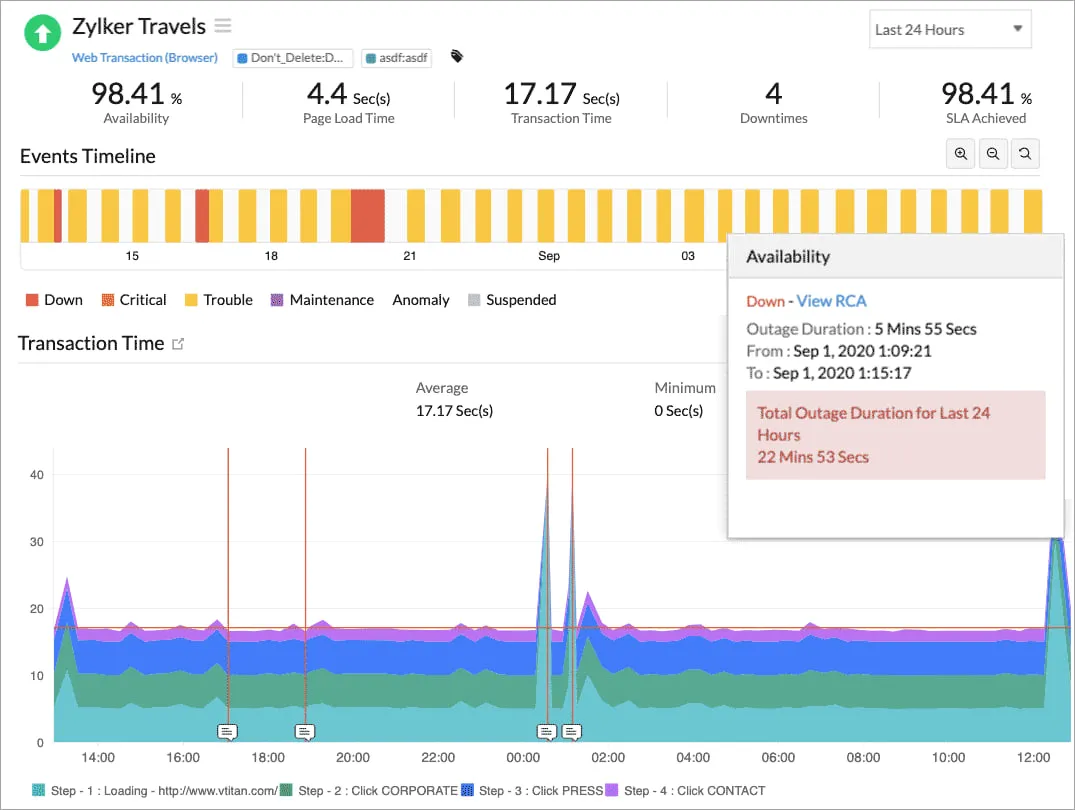
Site24x7 deckt synthetische Benutzerflüsse, Server- und Netzwerküberwachung, Cloud-Infrastruktur, Anwendungen und mehr ab. Für kleine und mittlere Teams ist dies ein gutes Tool, das vollständige Abdeckung bietet.
Wichtige Vorteile
- Überwachung für Web, Server, Netzwerk, Anwendungen;
- Unterstützung von Infrastrukturprotokollen;
- Einfache und schrittweise Lernmöglichkeiten;
- Flexible Preisgestaltung und gutes Preis-Leistungs-Verhältnis.
Am besten geeignet für: Budgetbewusste Teams, die “All-in-One”-Grundlagen benötigen.
Real-Life-Szenario: Sie sind der einzige DevOps-Ingenieur in einem 50-Personen-Startup. Sie müssen Ihre Website, den VPN-Router Ihres Büros und Ihre AWS-Rechnung mit einem begrenzten Budget überwachen.
Die Lösung: Sie verwenden Site24x7, um grundlegende Uptime-Pings und einen Server-Agent auf Ihren Linux-Boxen einzurichten. Es ist ein “einrichten und vergessen”-Tool, das Ihnen 80% der Sichtbarkeit teurer Tools zu 20% der Kosten bietet.
6. Pingdom

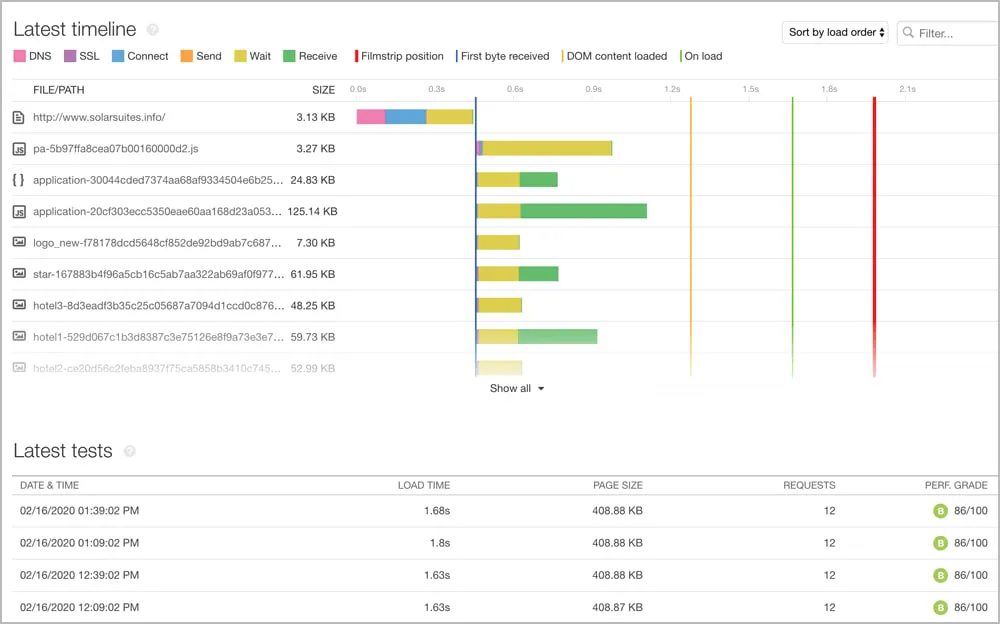
Pingdom ist ein webbasiertes synthetisches Überwachungstool. Zu seinen Funktionen gehören Seitenlade-Messungen und Simulationen von Benutzerreisen aus mehreren Standorten. Es ist eine großartige Wahl für alle, deren Fokus auf der Webüberwachung liegt.
Wichtige Vorteile
- Schnelle Konfiguration und Bereitstellung;
- Überprüfungen an mehreren Standorten zur Erkennung regionaler Probleme;
- Unterstützung für mehrstufige Überwachung;
- Echtzeit-Benachrichtigungen und Leistungsberichte.
Am besten geeignet für: Marketing- & Geschäftspartner.
Real-Life-Szenario: Ihr CMO möchte eine einfache “Öffentliche Statusseite” einrichten, um den Kunden zu zeigen, dass die Website zuverlässig ist.
Die Lösung: Sie richten einen einfachen Pingdom-Check ein. Es ist kostengünstig und hochzuverlässig. Wenn die Website ausfällt, wird ein Update der “Statusseite” ausgelöst, das Ihre Benutzer informiert, ohne Ihre internen komplexen SRE-Dashboards offenzulegen.
7. Checkly

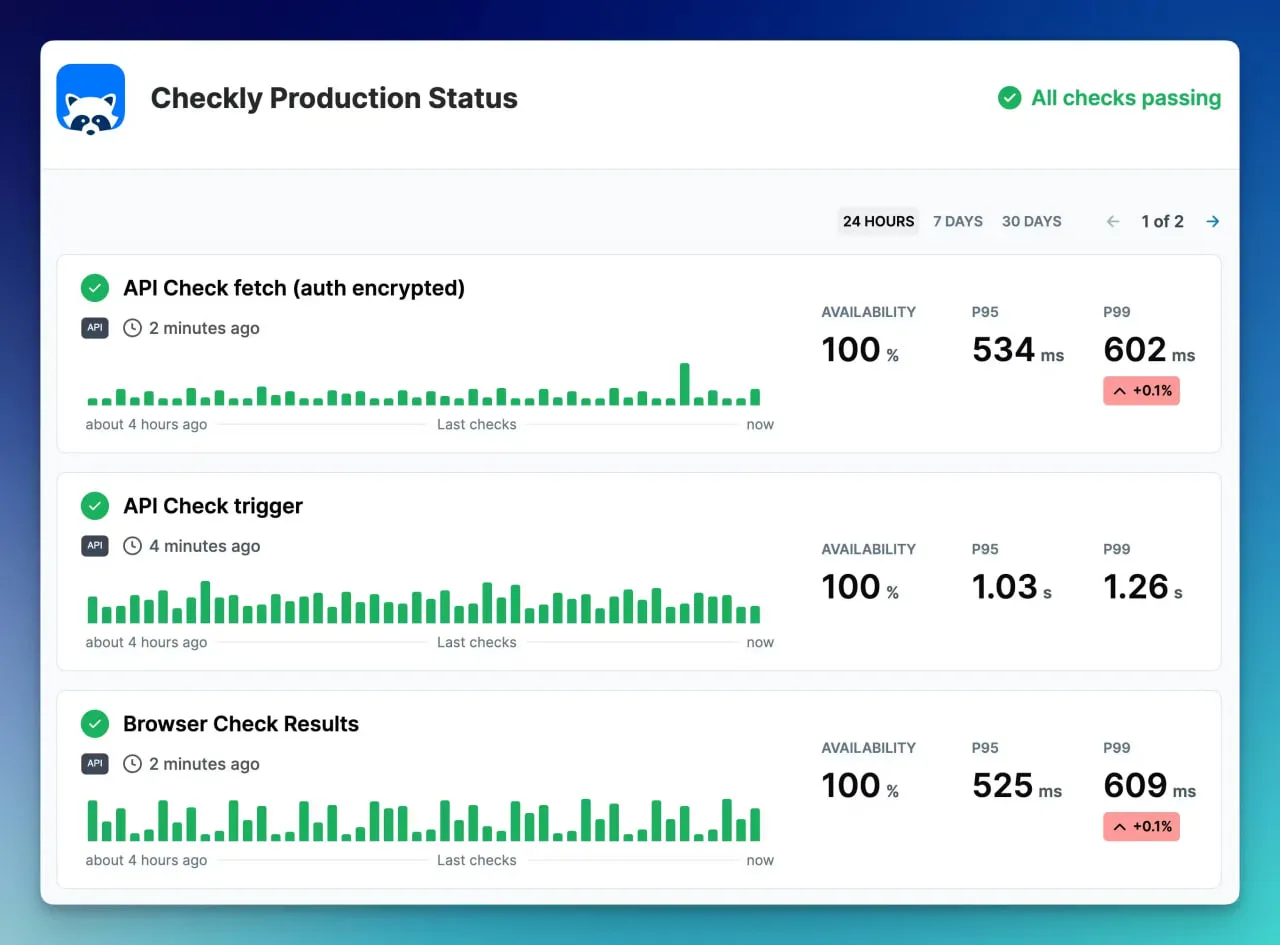
Checkly ist für Entwickler gedacht, da es JavaScript- und Playwright-Skripting betont, um Checks zu definieren. Dies macht es ideal für Personen, die programmieren können.
Wichtige Vorteile
- Hochgradig anpassbare synthetische Checks über Code;
- Lässt sich leicht in CI/CD-Pipelines integrieren;
- Gut für API- und browserbasierte Überwachung;
- Leichtgewichtig, modernes UI und Entwickler-Tools-Orientierung.
Am besten geeignet für: Moderne Frontend- & QA-Engineering (Playwright-First).
Real-Life-Szenario: Ihr Team bewegt sich in Richtung eines “You build it, you run it”-Modells. Ihre Entwickler verwenden bereits Playwright für lokale Tests und möchten dieselben Skripte zur Überwachung der Produktion verwenden.
Die Lösung: Sie integrieren Checkly in Ihre GitHub-Aktionen. Jedes Mal, wenn ein PR zusammengeführt wird, aktualisiert Checkly automatisch Ihre Produktions-“Heartbeat”-Monitore mit demselben Code, den Ihre Entwickler für Tests geschrieben haben.
8. Prometheus
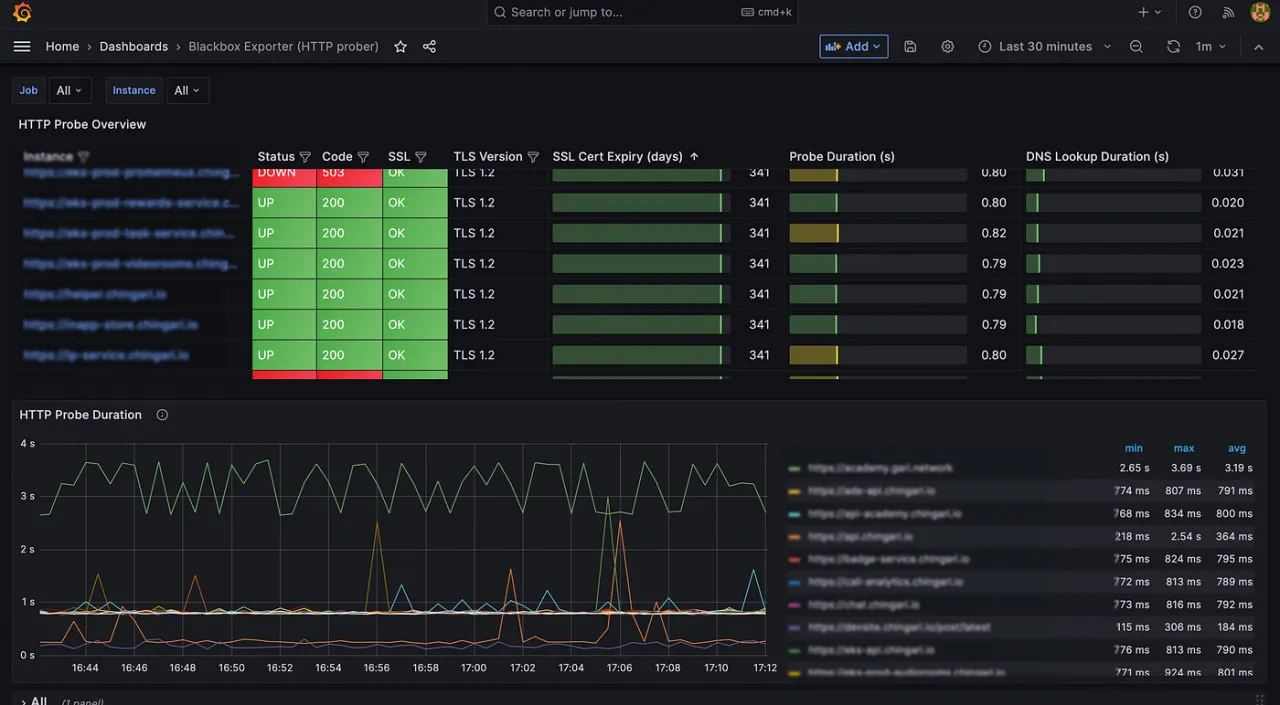
Prometheus ist der CNCF-ausgezeichnete “Goldstandard” für cloud-native Überwachung. Es hat das pull-basierte Metrikenmodell und die Verwendung von multidimensionalen Labels, die für die Verfolgung flüchtiger Kubernetes-Pods unerlässlich sind, eingeführt.
Wichtige Vorteile
- Nahtlose automatische Entdeckung für Kubernetes-Dienste und -Container.
- Eine leistungsstarke Abfragesprache, die für rechenintensive Operationen (z. B. Berechnung der 99. Perzentile-Latenz) entwickelt wurde.
- Jeder Server ist eigenständig und hat keine externe Datenbankabhängigkeit, was ihn während Ausfällen widerstandsfähig macht.
Am besten geeignet für: Kubernetes- & Mikroservices-Auto-Scaling.
Real-Life-Szenario: Sie betreiben eine Einzelhandels-API auf EKS (Amazon Kubernetes Service). Während eines “Flash Sales” spinnt Ihr HPA (Horizontal Pod Autoscaler) 200 neue Pods hoch.
Die Lösung: Prometheus entdeckt diese Pods automatisch über die Kubernetes-API, erfasst ihre Metriken sofort und warnt Sie, wenn die p99-Latenz über die gesamte Flotte 200 ms überschreitet – ohne dass Sie jemals manuell eine einzige IP-Adresse zu einer Konfigurationsdatei hinzufügen müssen.
9. Zabbix
Zabbix ist das “Schweizer Taschenmesser” der Infrastrukturüberwachung. Es ist eine zentrale, unternehmensbereite Plattform, die sich hervorragend für die Überwachung “gemischter Bestände” eignet – wo Sie eine Mischung aus modernen Linux-Servern, Legacy-Windows-Boxen und physischer Netzwerktechnik haben.
Wichtige Vorteile
- Zabbix umfasst Dashboards, Alarme und Berichterstattung in einer einzigen nativen Weboberfläche.
- Erstklassige Unterstützung für physische Hardware (Router, Switches und sogar Thermometer im Serverraum).
- Wenn Sie ein Skript dafür schreiben können (Python, Bash, Go), kann Zabbix es überwachen.
Am besten geeignet für: Hybride Infrastruktur & vielfältige Netzwerkbestände.
Real-Life-Szenario: Sie verwalten ein Universitätsnetzwerk. Sie müssen 500 virtuelle Maschinen, 200 Cisco-Switches und die Temperatur von drei verschiedenen Rechenzentren überwachen.
Die Lösung: Sie verwenden Zabbix mit Aktiven Agenten für die VMs und SNMP für die Switches. Sie erstellen eine “Netzwerkkarte” in der Zabbix-UI, die rot wird, wenn ein Kern-Switch ausfällt, sodass Sie genau sehen können, welche Server durch den Hardwareausfall isoliert sind.
10. Nagios (Core & XI)
Der “Großvater” der Überwachung. Nagios basiert auf einer einfachen “Plugin”-Architektur – es führt ein Skript aus, betrachtet den Rückgabewert (0, 1, 2) und warnt entsprechend. Es ist legendär für seine Stabilität, wird aber für seine Benutzeroberfläche aus den 1990er Jahren und die Konfigurationsprobleme kritisiert.
Wichtige Vorteile
- Wenn es in einem Rechenzentrum existiert, hat jemand in den letzten 25 Jahren bereits ein Nagios-Plugin dafür geschrieben.
- Die Kern-Engine ist unglaublich leichtgewichtig und kann auf minimaler Hardware betrieben werden.
- Es folgt einem einfachen “Check -> Ergebnis -> Alarm”-Fluss, der leicht zu beheben ist.
Am besten geeignet für: Stabile, Legacy- oder “statische” Umgebungen.
Real-Life-Szenario: Sie verwalten eine Reihe von mission-critical “Air-Gapped”-Servern in einer sicheren Einrichtung. Diese Server ändern sich nie, sie skalieren nicht automatisch und müssen 24/7/365 verfügbar bleiben.
Die Lösung: Sie verwenden Nagios Core. Es ist rocksolide und wird bei einem Update nicht ausfallen. Sie verwenden ein einfaches check_disk und check_ssh Plugin. Es sendet eine einzige, zuverlässige E-Mail, sobald ein Hardware-RAID ausfällt, und das ohne “SaaS”- oder Cloud-Abhängigkeiten.
11. SolarWinds NPM

SolarWinds Network Performance Monitor (NPM) spezialisiert sich auf die Überwachung von Netzwerkgeräten und Pfaden. Es verfolgt Erreichbarkeit, Hop-Latenz, Gerätegesundheit, Schnittstellenverkehr, SNMP-Metriken und Netzwerk-Topologie.
Wichtige Vorteile
- Außergewöhnliche Sichtbarkeit von Netzwerkpfaden, Hops und Schnittstellen;
- SNMP- und NetFlow-Unterstützung, gerätebezogene Metriken;
- Einblicke in Netzwerkengpässe und Topologieprobleme;
- Starke Diagnosen für netzwerkbezogene Ausfälle.
Am besten geeignet für: Netzwerkadministratoren & physische Infrastruktur.
Real-Life-Szenario: Benutzer beschweren sich, dass “das Internet langsam ist.” Sie vermuten ein Hardwareproblem im Serverraum oder einen schlechten Glasfaser-Hop zwischen Ihren Büros.
Die Lösung: Sie verwenden NetPath. Es zeigt Ihnen eine Hop-für-Hop-Karte des Netzwerkpfades. Sie sehen einen 200-ms-Latenzspike an einem bestimmten Cisco-Router in Ihrer Dallas-Niederlassung, was bestätigt, dass es sich um einen Hardwareengpass und nicht um einen Softwarefehler handelt.
12. LogicMonitor / ManageEngine OpManager
 LogicMonitor und ManageEngine sind Tools zur Überwachung von Unternehmensinfrastrukturen, die synthetische Module und Integrationen zur Benutzererfahrung bieten. Sie sind gut für die Überwachung von Geräten, Servern, VMs und Anwendungen.
LogicMonitor und ManageEngine sind Tools zur Überwachung von Unternehmensinfrastrukturen, die synthetische Module und Integrationen zur Benutzererfahrung bieten. Sie sind gut für die Überwachung von Geräten, Servern, VMs und Anwendungen.
Wichtige Vorteile
- Breite von Servern, Netzwerk- & Anwendungsinfrastruktur;
- Vorgefertigte Integrations- und Automatisierungskomfort;
- Perfektes Dashboard für Unternehmensoperationen;
- Einige Optionen für die Integration synthetischer Module.
Am besten geeignet für: Hybride IT & Managed Service Provider (MSPs).
Real-Life-Szenario: Sie verwalten die IT für ein Unternehmen mit 10 globalen Büros, die jeweils über eigene lokale Server, NetApp-Speicher und VMware-Cluster verfügen, die alle mit Azure verbunden sind.
Die Lösung: Sie verwenden die Collector-Architektur von LogicMonitor. Sie entdeckt automatisch alle 2.000+ Geräte in Ihrem Netzwerk und erstellt ein “Enterprise Dashboard”, das die Gesundheit Ihres physischen Speichers, virtueller Maschinen und Cloud-Instanzen in einer Ansicht zeigt.
Wie wählt man seinen Überwachungs-Stack aus?
Die Auswahl einer Überwachungs-Suite geht weniger darum, “das beste Tool zu finden” und mehr darum, die Lücke zwischen einem Vorfall und seiner Lösung zu minimieren. Für ein modernes DevOps- oder SRE-Team sollte der Entscheidungsprozess die folgenden Punkte priorisieren:
1. Abdeckung vs. Tool-Sprawl bewerten
Fragen Sie sich, ob Ihr Team realistisch einen “Best-of-Breed”-Stack verwalten kann (z. B. Prometheus für Metriken, Checkly für Skripte und SolarWinds für das Netzwerk). Während spezialisiert, führt dies oft zu “Daten-Silos.” Einheitliche Plattformen wie Dotcom-Monitor oder Datadog reduzieren den Kontextwechsel während hochdruckbelasteter Ausfälle, indem sie synthetische Fehler direkt mit der Infrastrukturgesundheit korrelieren.
2. Automatisierung und IaC-Unterstützung priorisieren
In einer cloud-nativen Umgebung ist manuelle Konfiguration eine Haftung. Stellen Sie sicher, dass Ihr gewähltes Tool Terraform, Pulumi oder eine umfassende CLI unterstützt. Wenn Sie einen synthetischen Check nicht als Teil eines Service-Deployments bereitstellen können, wird das Tool letztendlich zu einem Engpass für Ihre Engineering-Geschwindigkeit.
3. Signal-Rausch-Verhältnis bewerten
Die größte Bedrohung für ein SRE ist Alarmmüdigkeit. Suchen Sie nach Tools, die eine ausgeklügelte Alarmlogik bieten – wie “X Fehler aus Y Standorten” – um vorübergehende Netzwerkprobleme herauszufiltern. Vermeiden Sie Plattformen, die einen “One-Size-Fits-All”-Schwellenwert erzwingen, was oft zu “Wolf schreien” und ignorierten Benachrichtigungen führt.
4. Gesamtkosten des Eigentums (TCO) analysieren
Über den Listenpreis hinaus sollten Sie den operativen Aufwand berücksichtigen. Open-Source-Lösungen wie Zabbix oder Prometheus sind in der Lizenzierung “kostenlos”, aber teuer in den Ingenieurstunden, die für Wartung, Patching und Skalierung erforderlich sind. SaaS-Plattformen tauschen höhere Lizenzkosten gegen reduzierte “Toil”-Kosten, sodass Ihr Team sich auf die Zuverlässigkeit der Website und nicht auf die Wartung des Überwachungsservers konzentrieren kann.
Viele Teams übernehmen einen geschichteten Stack oder setzen voll auf einheitliche Plattformen wie Dotcom‑Monitor. Was für Sie am besten ist, hängt von Ihrem Budget, System, Teamgröße und Teamexpertise ab.
Fazit
Im Jahr 2026 ist das “beste” Tool das, das die Silos zwischen Ihren DevOps-, SRE- und QA-Teams beseitigt. Wenn Sie eine komplexe, cloud-native Umgebung verwalten, bieten Datadog oder Dynatrace unvergleichliche Korrelation, wenn auch zu einem Premiumpreis. Für Teams, die einen robusten, einheitlichen Ansatz suchen, der tiefe Protokollprüfungen mit globalen synthetischen Transaktionen kombiniert, ohne die “Enterprise-Steuer”, bietet Dotcom-Monitor das pragmatischste Gleichgewicht zwischen “Outside-In” und “Inside-Out”-Sichtbarkeit.
Letztendlich sollte Ihr Ziel sein, Monitoring als Code zu behandeln. Priorisieren Sie Tools mit starker API-Unterstützung und Terraform-Anbietern, damit Ihre Überwachung sich so schnell entwickelt wie Ihre Infrastruktur.
Frequently Asked Questions
- Verwenden Sie Alarme über ein zentrales System
- Verwenden Sie Schweregrade und Schwellenwerte sinnvoll
- Unterdrücken Sie während Wartungsfenstern
- Gruppieren Sie verwandte Alarme und filtern Sie Duplikate
- Optimieren Sie basierend auf historischen Fehlalarmen
