Для выполнения сценариев нагрузочного теста, созданных с использованием контекстных параметров, мы используем CSV-файлы в качестве внешнего набора данных, в котором хранятся значения параметров (Загрузка динамических переменных (параметров контекста) в тестовый сценарий). Нагрузочный тест можно сделать более реалистичным, настроив использование строк значений из загруженного CSV-файла. Для этого перейдите на страницу Тестовый сценарий в разделе Параметры контекста и настройте параметры Диапазон строк значений и Использование строк.
Настройка диапазона строк значений
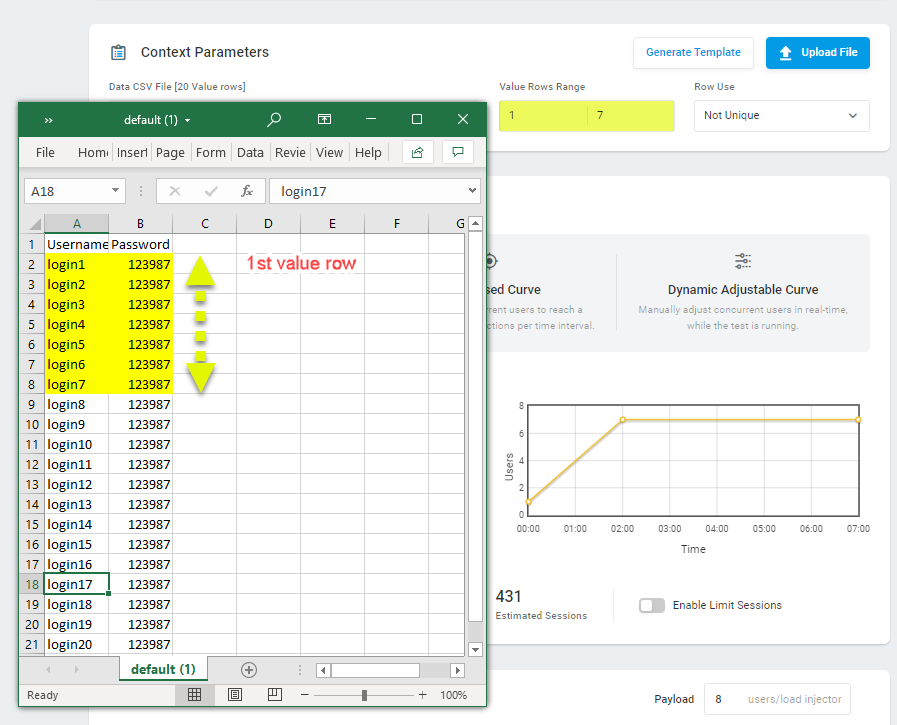
По умолчанию в тесте будут использоваться все строки значений из загруженного CSV-файла. Однако в поле Диапазон строк значений можно явно указать диапазон, из которого необходимо выбрать значения. Первая строка в CSV-файле, содержащая значения параметров контекста, считается первой строкой значений. Строка с именами параметров не учитывается.
Настройка режима использования строки
В поле Использование строки можно указать, как в тесте будет осуществляться доступ к строкам значений из CSV-файла.
- По умолчанию используется режим Not Unique и доступ к строкам осуществляется в случайном порядке.
- Как правило, если веб-приложение не позволяет использовать одни и те же данные одновременно (например, одновременный вход не поддерживается), рекомендуется использовать режим «Уникальный для каждого пользователя».
- В случае, когда необходимо нагрузочное тестирование с уникальными пользователями, использующими уникальные данные (например, каждый раз авторизоваться под новым логином), рекомендуется использовать режим Unique per Session.
Например, рассмотрим базовый нагрузочный тест. План выполнения, представленный на рисунке ниже, имеет 2-минутную продолжительность устройства (время, необходимое одному пользователю для выполнения тестового сеанса).
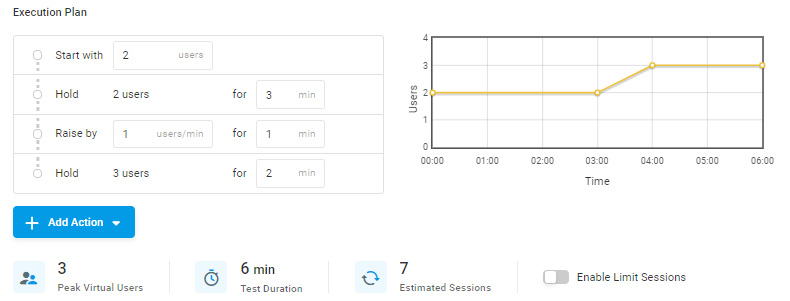
Далее давайте подробнее рассмотрим режим row Use и то, как система использует CSV-файл для выполнения описанного теста в каждом режиме.
Не уникальный
По умолчанию система выбирает и передает случайное значение виртуальному пользователю каждый раз, когда виртуальный пользователь начинает тестовый сеанс. В этом случае значения из одной строки могут использоваться одновременно разными пользователями (см. раздел «Строка 4» на рисунке ниже) и более одного раза одним и тем же (см. строку 1 ниже) или разными виртуальными пользователями во время тестового запуска.
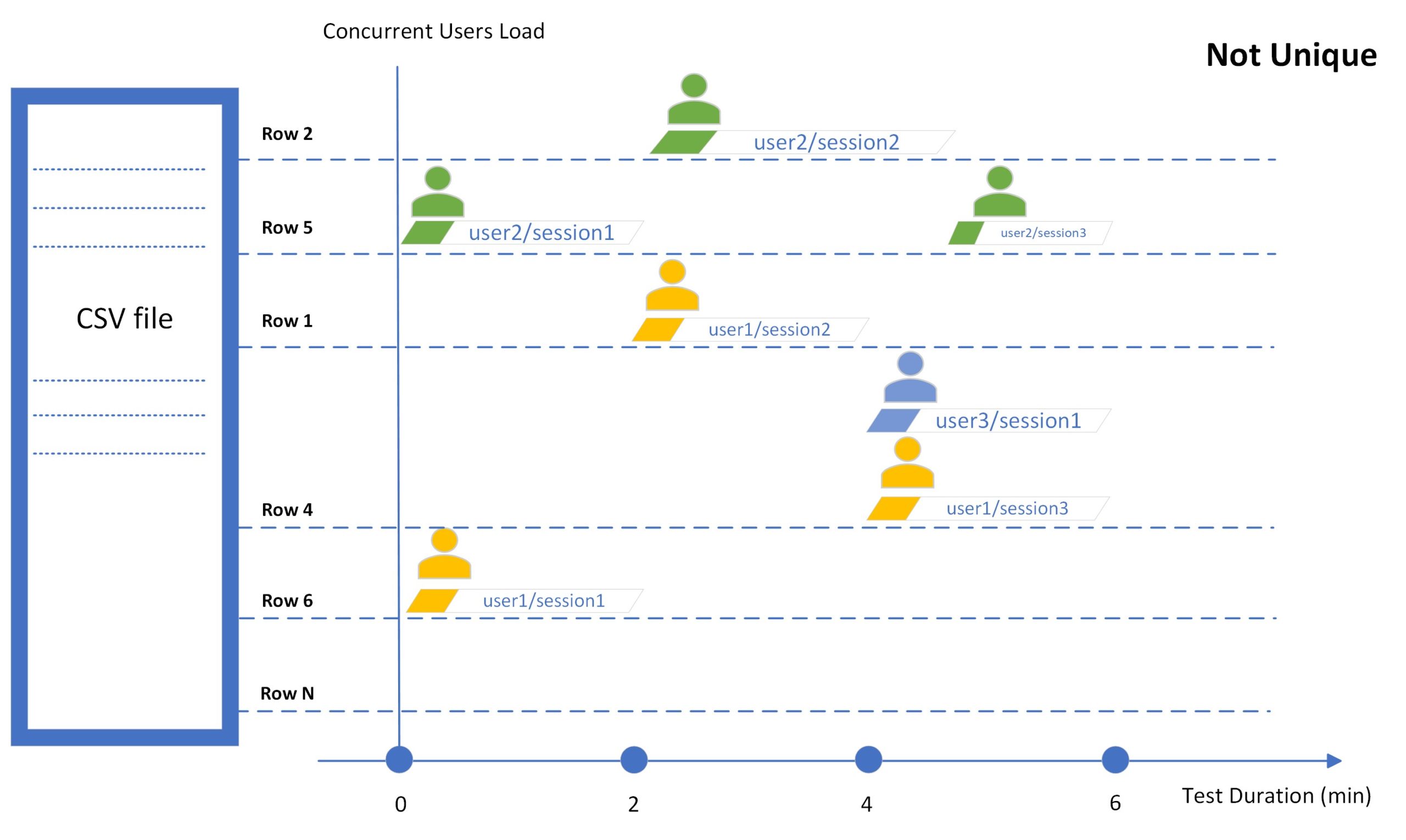
Если задать диапазон строк в одну строку, все тестовые сеансы будут выполняться с использованием значений из одной строки во время тестового запуска. Например, все виртуальные пользователи будут использовать одно и то же имя пользователя для выполнения транзакций регистрации или одно и то же ключевое слово для выполнения транзакций поиска.
Уникальность для каждого сеанса
В режиме Unique per Session система использует строку уникального значения для каждого тестового сеанса. Поэтому каждая строка значений будет использоваться только один раз во время тестового запуска.
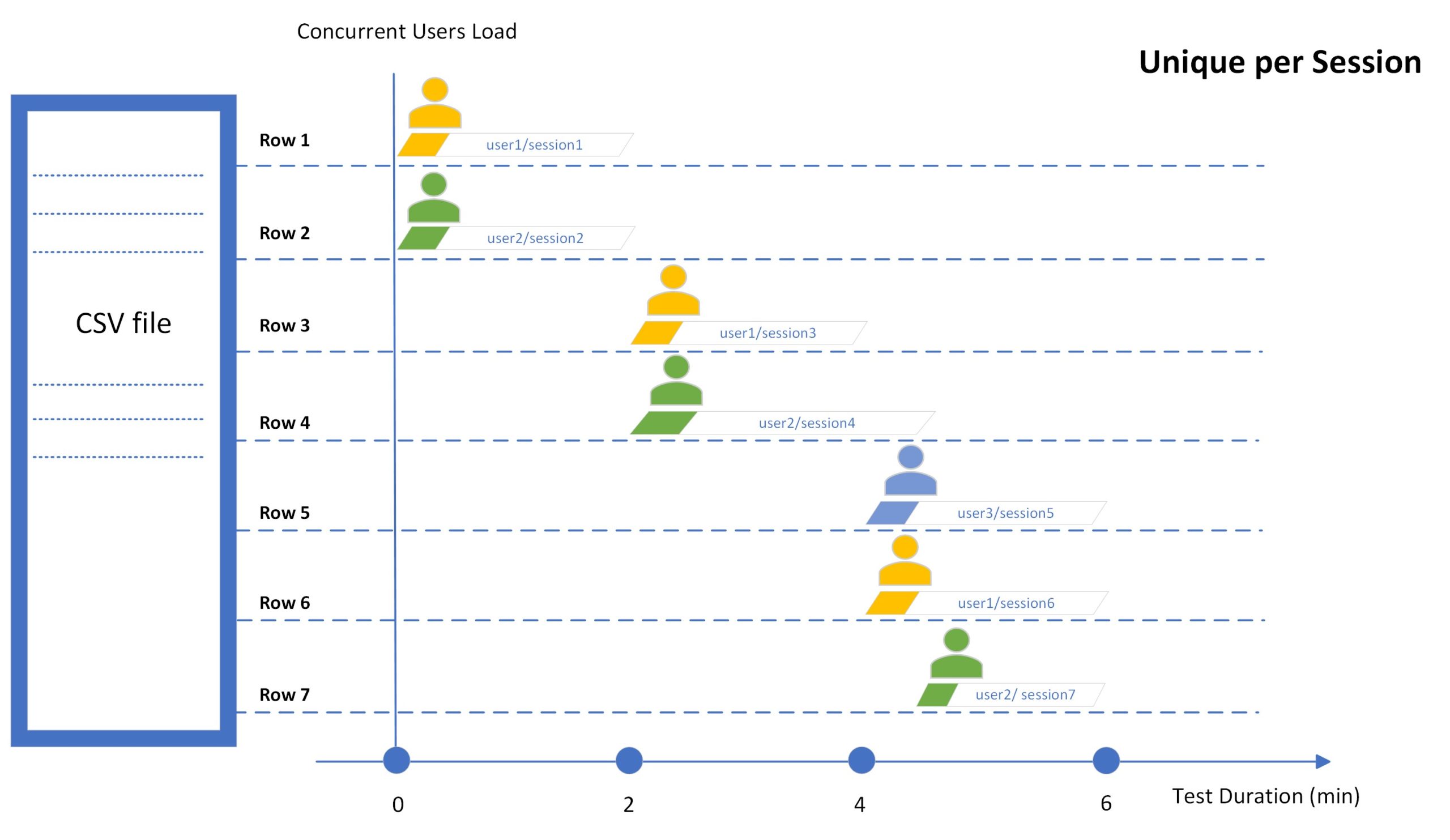
Обратите внимание, что при выборе режима «Уникальное для каждого сеанса» число сеансов в тесте будет автоматически ограничено количеством строк значений в переданном CSV-файле или диапазоном строк значений, если он указан (см. статью Ограничение числа тестовых сеансов).
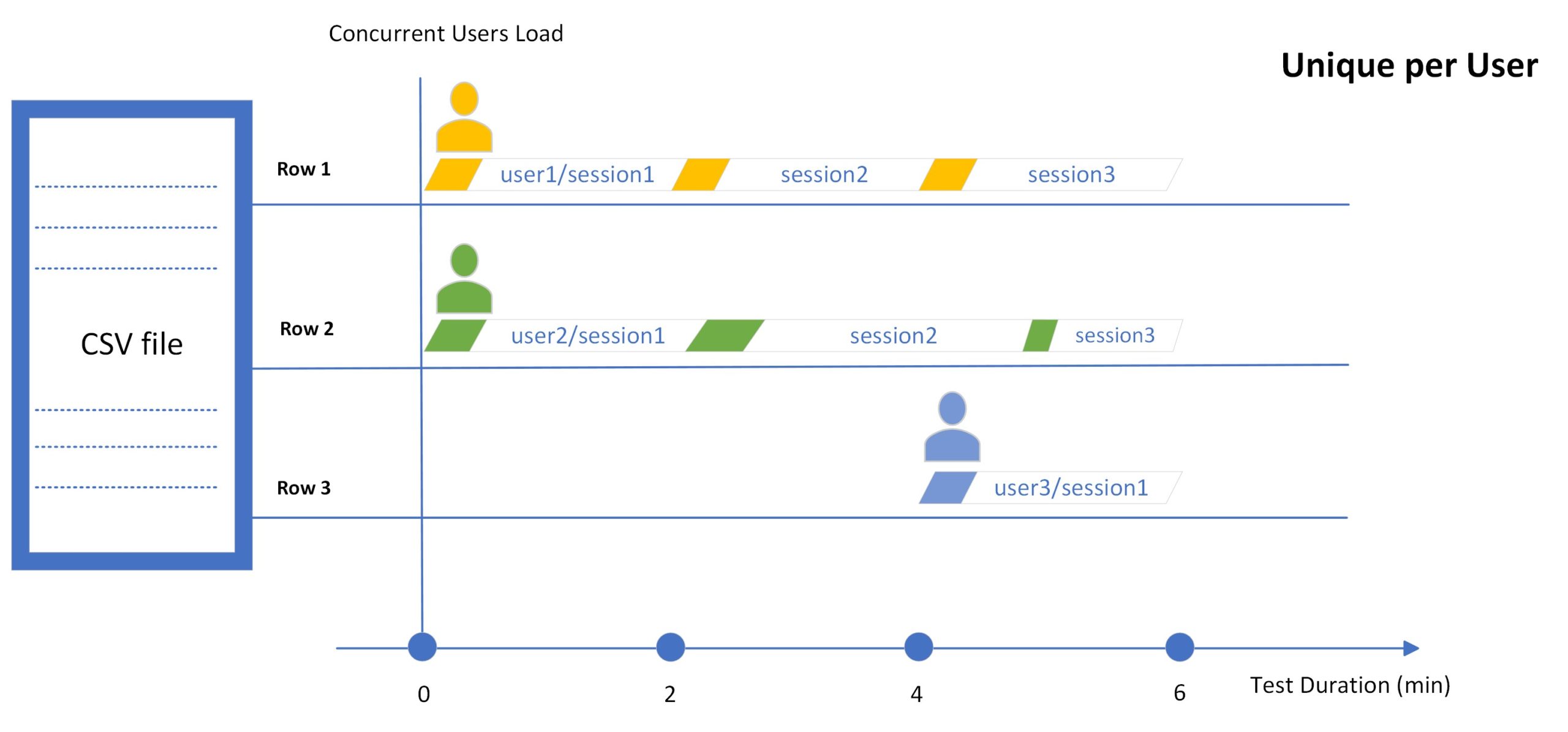
Уникальность на пользователя
В режиме Unique per User система использует значения из уникальной строки только с одним виртуальным пользователем во время тестового запуска. Обратите внимание, что в этом режиме число виртуальных пользователей будет ограничено количеством строк значений в CSV-файле или диапазоном строк значений, если он указан.