
このアプローチでは、Dotcom-Monitor が応答を「アップ」または「ダウン」応答として解釈する方法を慎重に定義する機能が提供されます。 これは、フィルターを使用して実行されます。
フィルタ処理では、次の調整可能な条件を使用して、アップ/ダウン 状態を定義します。
- 指定した時間分のエラーが報告される
- 指定した数のエージェントによってエラーが確認される
- 指定された数のタスクでエラーが検出されました。
すべてのフィルタとその設定は、フィルタの構成で使用できます > 。 フィルターがデバイスに適用されると、デバイスのすべての通知はフィルターの条件に基づきます。 「デフォルトフィルタ」は、すべての新しいデバイスに割り当てられます。 デフォルトのフィルタはバランスの取れた設定で、ほとんどの監視デバイスに適しています。
稼働時間/ダウンタイム計算
ダウンタイム計算の計算式は次のとおりです。

1. ダウンタイム期間 は、フィルタ内の設定に直接関連付けられています。
- ダウンタイム期間は、フィルタの条件が満たされたときに開始されます。 たとえば、エラーを報告するエージェントの数がフィルタで指定されたエージェントの数と等しく、指定された条件も分数とタスク数で満たされると、ダウンタイムアラートが送信されます。
- 稼働時間は、フィルターの条件が満たされなくなった時点で開始されます。 具体的には、 アップ時間 は、エージェント、分、またはタスクの数が「アップ」成功を報告し、もはやフィルター処理された「ダウン」条件に必要な条件を満たしていないときに開始します。 たとえば、エージェントが受信したエラー(「ダウン」)応答の数が、フィルターで設定されているように、エージェントが必要とするエラー(「ダウン」)応答の数より少なくなると、「上」状態が示されます。
2. 「未定義」状態の期間。 監視に関与する各エージェントのステータスが Undefined になったときに 、未定義状態を設定できます。 エージェントが一定時間内に応答 (エラーまたは成功) を提供しない場合、エージェントのステータスは 未定義 と見なされます。
応答時間の待機時間 = (エージェント全体の数 +1) × 監視頻度 + 15 分
たとえば、3つの監視エージェントと5分の監視頻度を使用します。 各エージェントは 、応答待機時間 = (3+1) ×5+15 分 = 35 分の応答を待機します。 時間が経過し、応答が受信されないと、エージェントは 未定義と報告します。
3. 「延期」状態の期間。 デバイスをいつでも延期すると、再び有効になるまで監視アクティビティが停止します。
4. 期間はスケジュールによって除外されます。アップタイム/ダウンタイム計算に大きな影響を与えるもう 1 つのエンティティは、 スケジュールです。 これは、定期的な保守の間にモニターを管理するためのオプションです。 監視は、特定の曜日に対して、また 1 日の特定の時間と分に対して延期できます。 スケジュールを設定するには、 指示に従います。
例:
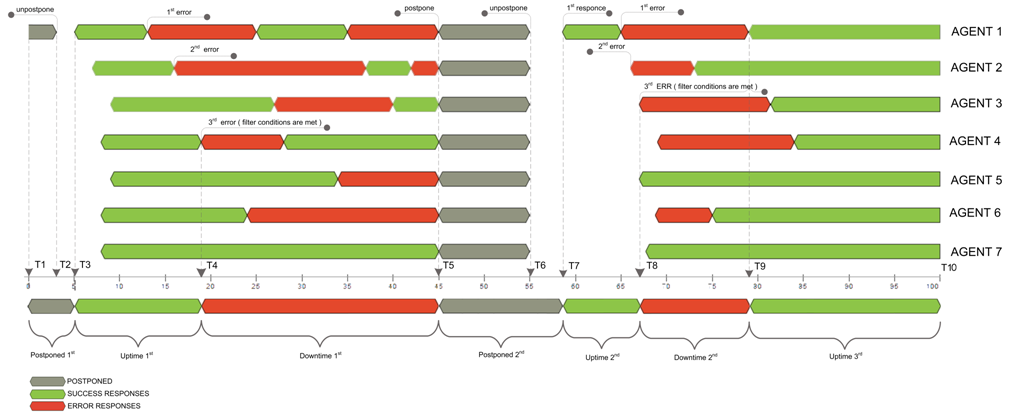
7 つの場所からデバイスを監視し、3 つの場所が ダウンタイム 条件のエラーを報告する必要があることを設定したフィルターがあるとします。 まず、モニタリングノード(エージェント) 1) 残りがまだ成功を報告している間にエラーを検出し、次に 2 番目のエージェント (エージェント) 2)と最後の3番目の1(エージェント4)は、この瞬間からすぐに 開始ダウンタイム を設定するためにフィルタをトリガするT4でエラーを検出します。 この間、エージェント報告エラーの数が調整済み 3 より多いため、停止状態は T5に設定されるまでは残ります。 T6 と T7 の間の時間差は、遅延 (セッションの処理時間の監視にはネットワーク転送の遅延と実行自体が含まれます) を最初に応答するという事実を示 ∆す図です。 繰り返しますが、エージェント 3 からの 3番目のエラーでのみダウンタイムに陥り、T9 応答でのみ Up 状態になり、失敗したエージェントの数がフィルターで調整された数より少なくなると、その状態はアップ状態になります。 この場合の最終的なダウンタイム % 計算式を次に示します。
